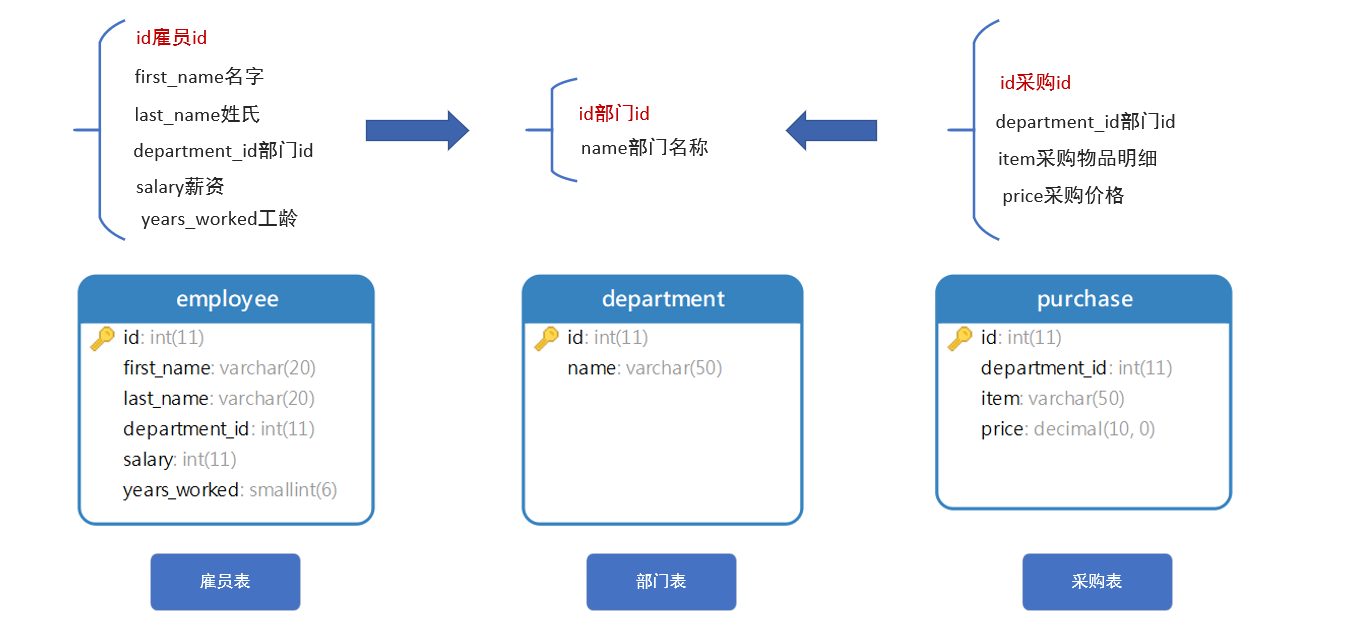
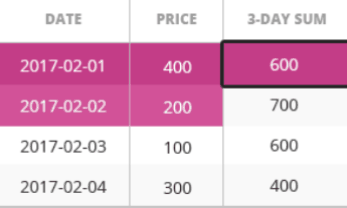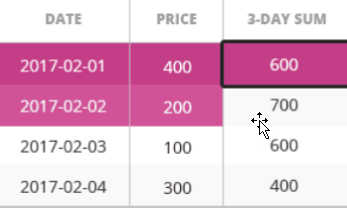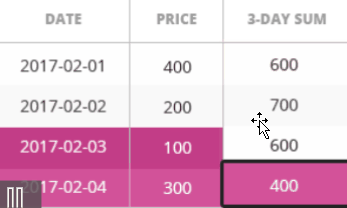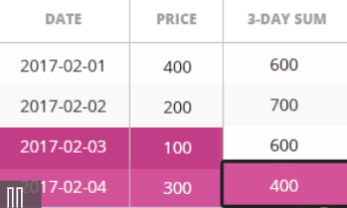
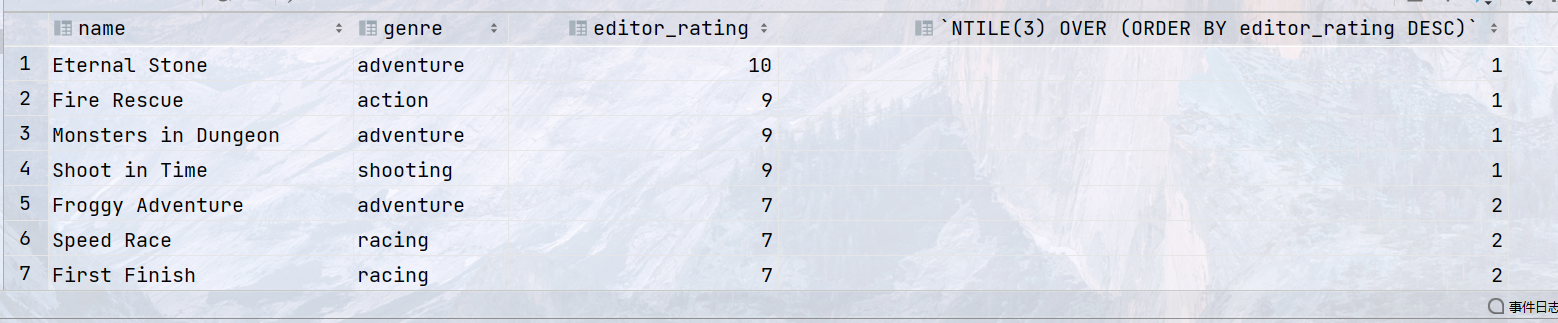
SELECT id, model, first_class_places, second_class_places, COUNT(id) OVER (PARTITION BY model) FROM train WHERE first_class_places > 30 AND second_class_places > 180;
PARTITION BY传入多列
需求:查询每天,每条线路速的最快车速
查询结果包括如下字段:线路ID,日期,车型,相同线路每天的最快车速
代码:
1 2 3 4 5 6 7 8 9
SELECT journey.id, journey.date, train.model, train.max_speed, MAX(max_speed) OVER(PARTITION BY route_id, date) FROM journey JOIN train ON journey.train_id = train.id;
SELECT journey.id, production_year, COUNT(journey.id) OVER(PARTITION BY train_id) as count_train, COUNT(journey.id) OVER(PARTITION BY route_id) as count_journey FROM train JOIN journey ON train.id = journey.train_id;
结果:
查询票价表,返回id, price, date ,并统计每天的在售车票的平均价格,每天的在售车票种类。(不统计运营车辆id为5的数据)
代码:
1 2 3 4 5 6 7 8 9 10
SELECT ticket.id, date, price, AVG(price) OVER(PARTITION BY date), COUNT(ticket.id) OVER(PARTITION BY date) FROM ticket JOIN journey ON ticket.journey_id = journey.id WHERE train_id != 5;
结果:
OVER(PARTITION BY x)的工作方式与GROUP BY类似,将x列中,所有值相同的行分到一组中
PARTITON BY 后面可以传入一列数据,也可以是多列(需要用逗号隔开列名)
代码:
1 2 3 4 5 6 7 8 9 10
SELECT ticket.id, date, price, AVG(price) OVER(PARTITION BY date), COUNT(ticket.id) OVER(PARTITION BY date) FROM ticket JOIN journey ON ticket.journey_id = journey.id WHERE train_id != 5;
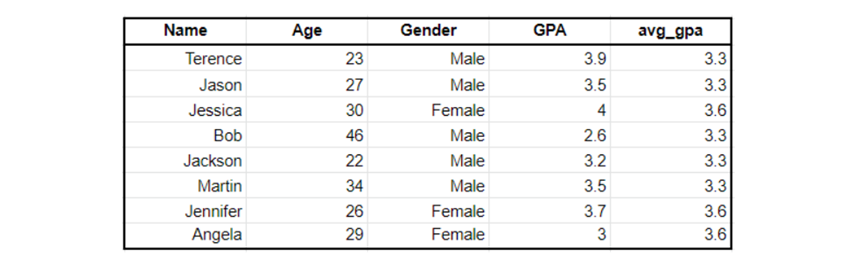
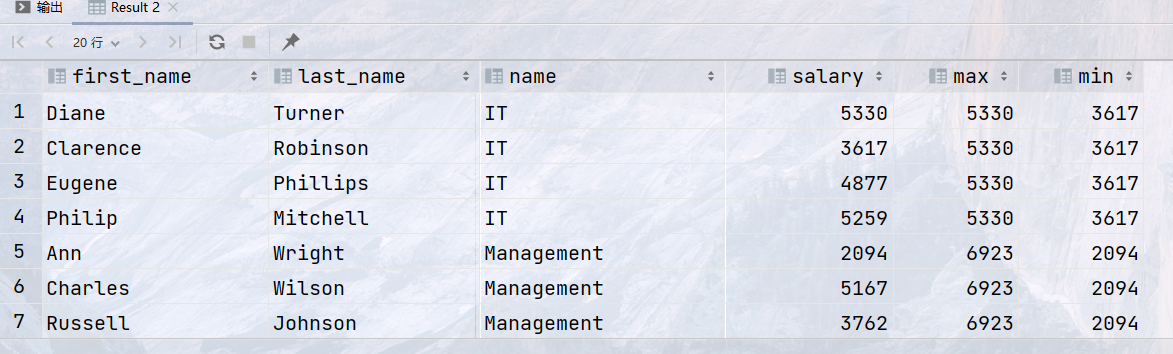
select first_name, last_name, d.name, salary, max(salary) over (partition by d.id) as max, min(salary) over(partition by d.id) as min from employee join department d on employee.department_id = d.id;
结果:
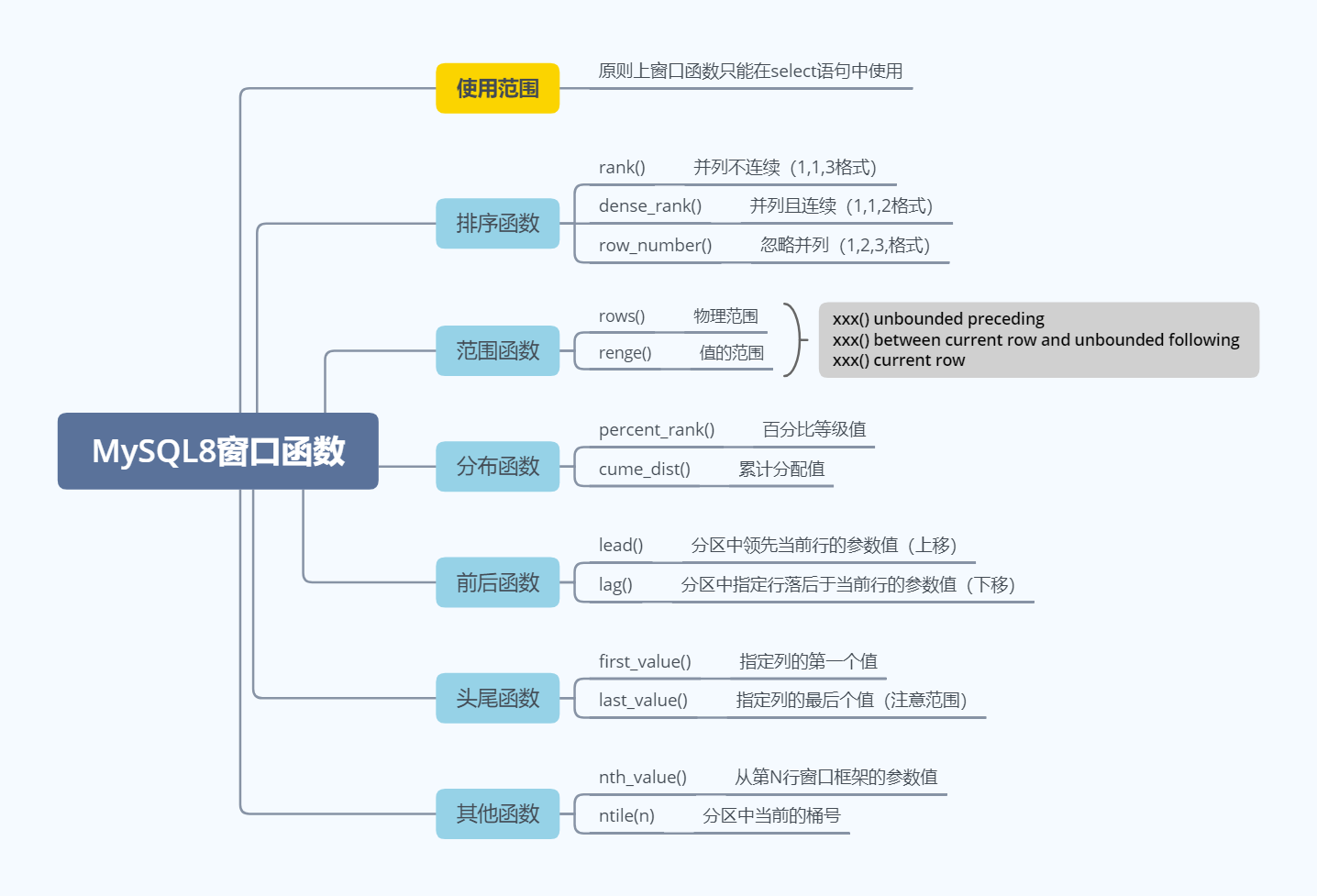
排序函数
排序函数
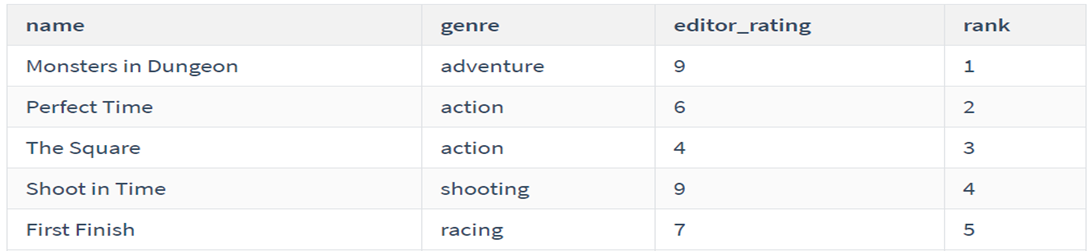
按游戏评分排序
代码:
1 2 3 4 5 6
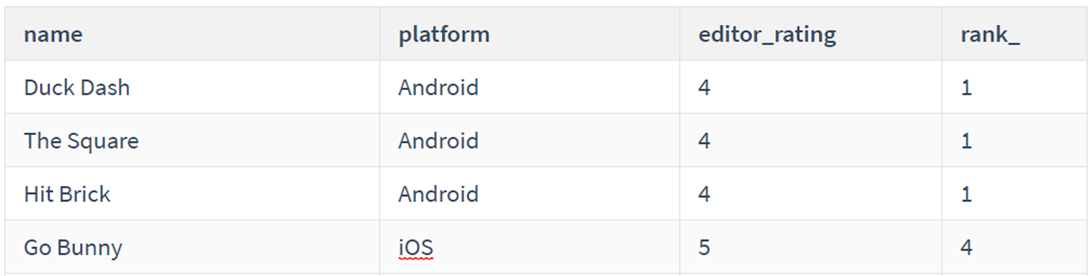
SELECT name, platform, editor_rating, RANK() OVER(ORDER BY editor_rating) as rank_ FROM game;
rank()并列不连续
结果:
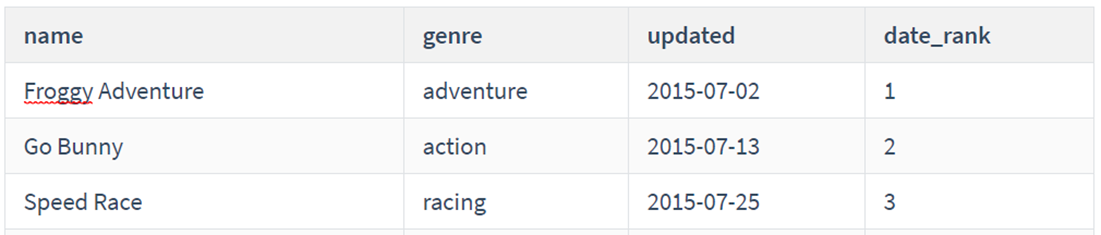
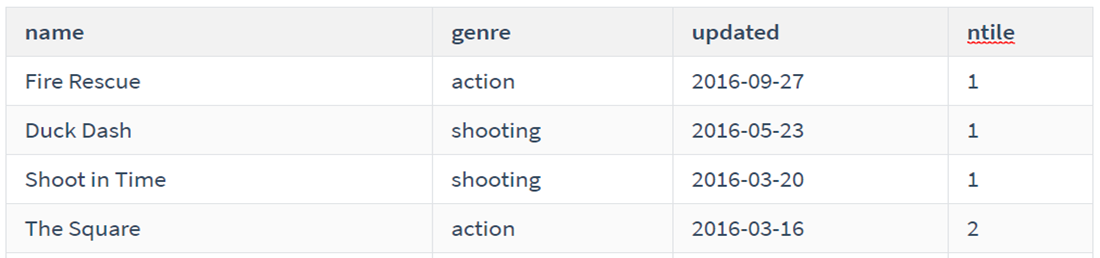
统计每个游戏的名字,分类,更新日期,更新日期序号
代码:
1 2 3 4 5 6
SELECT name, genre, updated, RANK() OVER(ORDER BY updated) as date_rank FROM game;
结果:
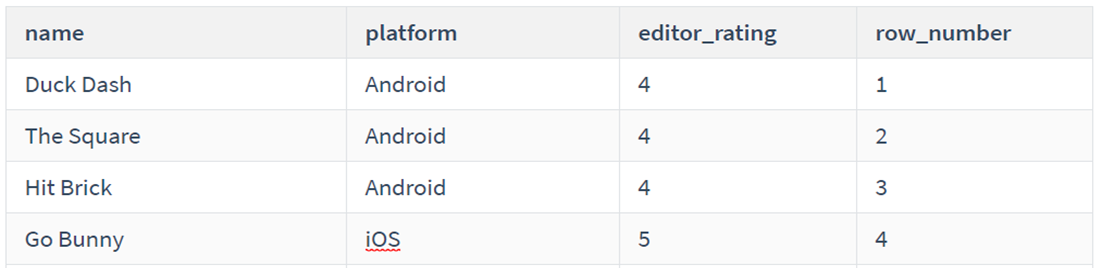
题目同上
代码:
1 2 3 4 5 6
SELECT name, platform, editor_rating, DENSE_RANK() OVER(ORDER BY editor_rating) as rank_ FROM game;
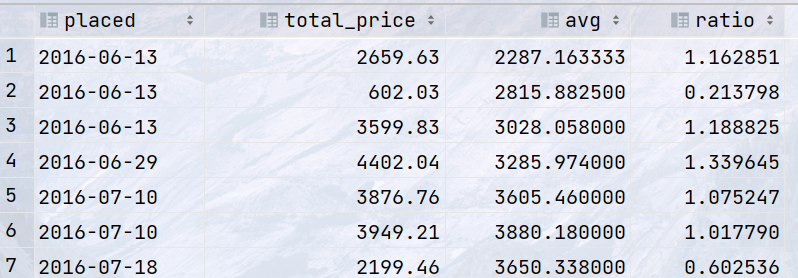
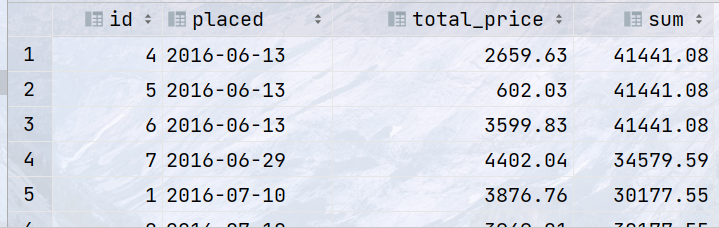
select placed, total_price, avg(total_price) over (order by placed ROWS between 2 preceding and 2 following) as avg, total_price / avg(total_price)over (order by placed ROWS between 2 preceding and 2 following) as ratio from single_order;
ROWS UNBOUNDED PRECEDING 等价于 BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
ROWS n PRECEDING 等价于 BETWEEN n PRECEDING AND CURRENT ROW
ROWS CURRENT ROW 等价于 BETWEEN CURRENT ROW AND CURRENT ROW
注意,这种简略的写法不适合 FOLLOWING的情况
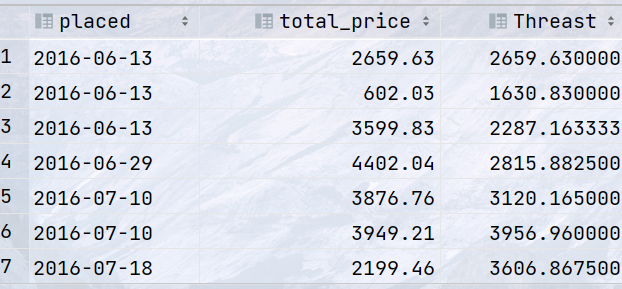
统计每个订单的下单日期,总价,每4个订单的平均价格(当前行以及前3行,按下单日期排序)
代码
1 2 3 4
select placed, total_price, avg(total_price) over (order by placed rows between 3 preceding and current row ) as Threast from single_order;
结果
RANGE()函数
和使用 ROWS一样,使用RANGE 一样可以通过 BETWEEN ... AND... 来自定义窗口
在使用RANGE 时,我们一般用
RANGE UNBOUNDED PRECEDING
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
RANGE CURRENT ROW
但是在使用RANGE 确定窗口大小是,一般 不与 n PRECEDING 或 n FOLLOWING 一起使用
使用ROWS,通过当前行计算前n行/后n行,很容易确定窗口大小
使用RANGE,是通过行值来进行判断,如果使用 3 PRECEDING 或 3 FOLLOWING 需要对当前行的值进行-3 或者+3操作,具体能选中几行很难确定,通过WINDOW FRAMES 我们希望定义的窗口大小是固定的、可预期的,但当RANGE 和 n PRECEDING 或 n FOLLOWING 具体会选中几行数据,跟随每行取值不同而发生变化,窗口大小很可能不固定。
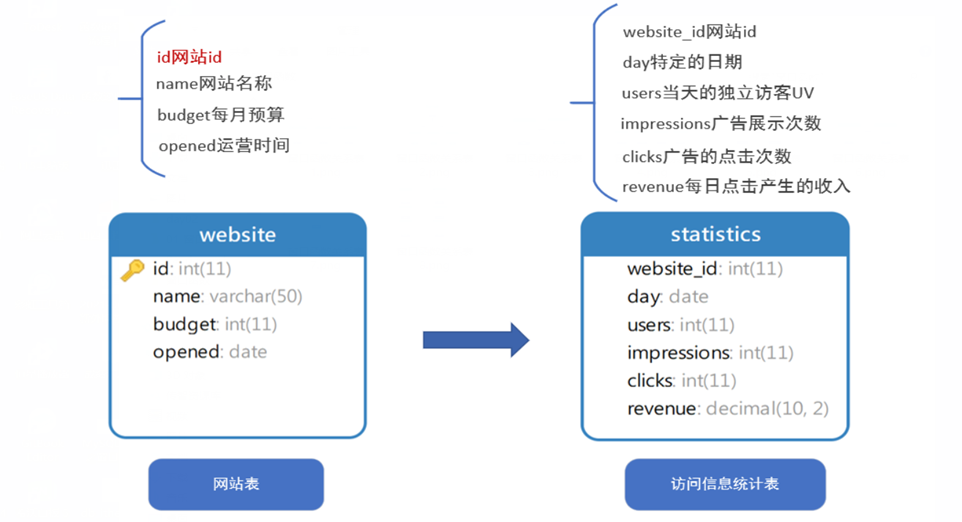
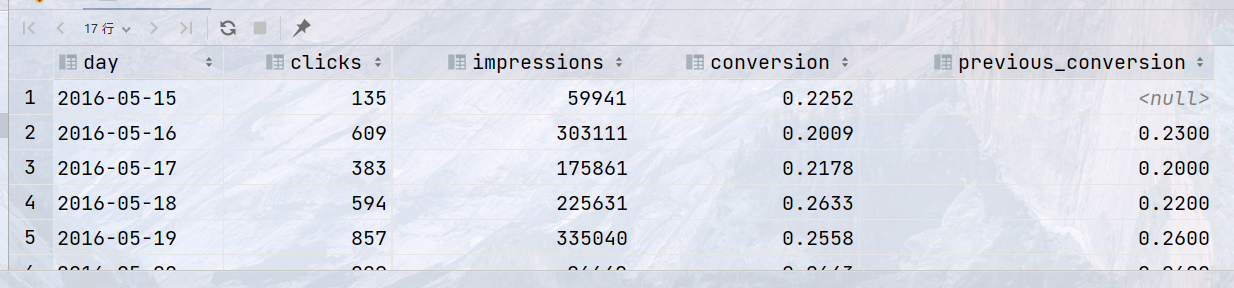
SELECT day, clicks, impressions, clicks / impressions * 100 AS conversion, LAG(clicks / impressions) OVER (ORDER BY day) * 100 AS previous_conversion FROM statistics WHERE website_id = 1 AND day BETWEEN '2016-05-15' AND '2016-05-31';
结果
first_value(x)与last_value(x)
first_value(x)
first_value(x)函数,从名字中能看出,返回指定列的第一个值
代码
1 2 3 4 5 6
SELECT name, opened, budget, FIRST_VALUE(budget) OVER(ORDER BY opened) FROM website;
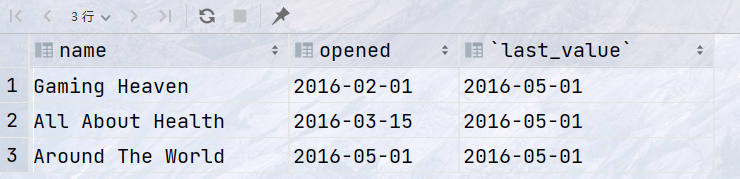
range/rows between unbounded preceding and unbounded following
代码
1 2 3 4 5 6 7
SELECT name, opened, LAST_VALUE(opened) OVER ( ORDER BY opened RANGE BETWEEN UNBOUNDED preceding and UNBOUNDED FOLLOWING ) AS `last_value` FROM website;
结果
综合案例:
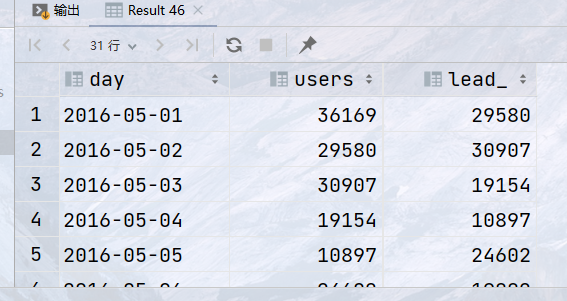
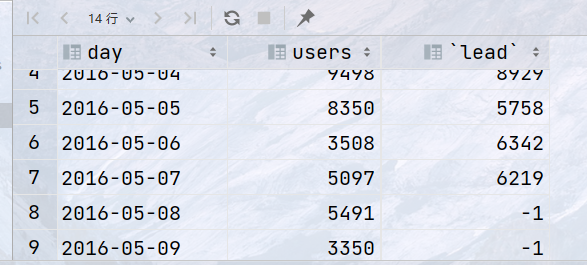
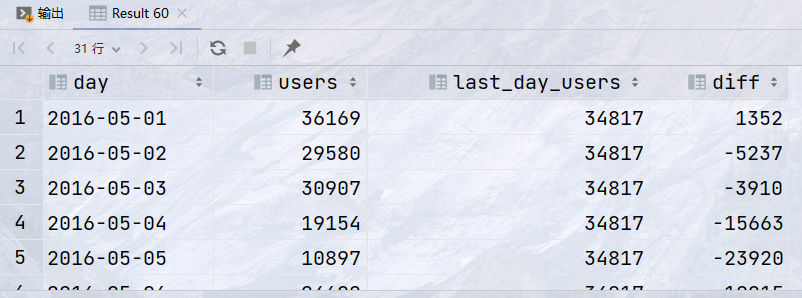
统计id为1的网站,每日的访问用户数,最后一天的访问用户数,每日用户数与最后一天用户数的差值
代码
1 2 3 4 5 6 7 8 9 10 11 12
SELECT day, users, LAST_VALUE(users) OVER ( ORDER BY day ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) `last_day_users`, users - LAST_VALUE(users) OVER ( ORDER BY day ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) `diff` FROM statistics WHERE website_id = 1;
结果
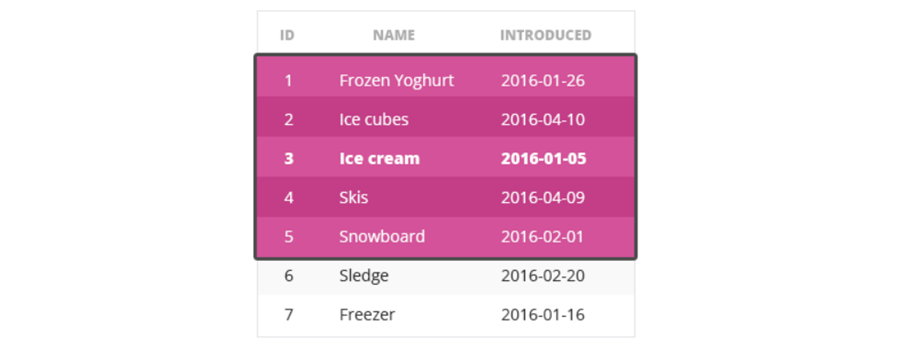
nth_value(x,n) 函数
简介:NTH_VALUE(x,n) 函数返回 x列,按指定顺序的第n个值
代码
1 2 3 4 5 6 7 8 9 10 11
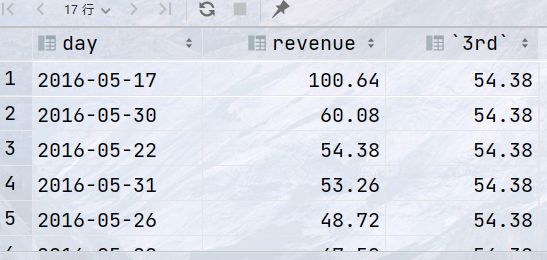
## 上面的SQL将数据按照开业日期排序,NTH_VALUE(opened,2) 返回开业日期排在第二位的值 ## 需要注意,我们需要调整window frame 否则某些情况下不能返回正确的数据 ## 提示:可以在排序的时候加上DESC 调整排序的顺序,配合 NTH_VALUE(x,n) 在某些场景下更加方便 select day, revenue, nth_value(revenue, 3) over (order by revenue desc rows between unbounded preceding and unbounded following) as 3rd from statistics where website_id = 2 and day between '2016-05-15' and '2016-05-31';
结果
代码
1 2 3 4 5 6 7 8
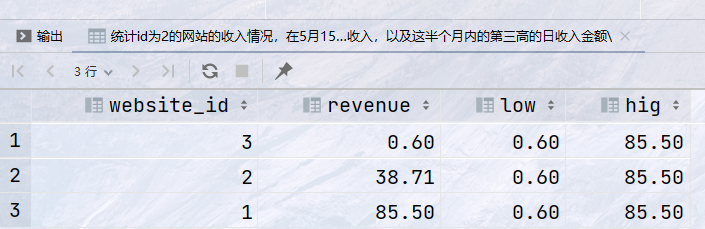
-- 统计id为2的网站的收入情况,在5月15和5月31日之间,每天的收入,以及这半个月内的第三高的日收入金额\ select website_id, revenue, first_value(revenue) over (order by revenue) as low, last_value(revenue) over (order by revenue rows between unbounded preceding and unbounded following) as hig from statistics where day = '2016-05-14';
结果
代码
1 2 3 4 5 6 7 8 9 10
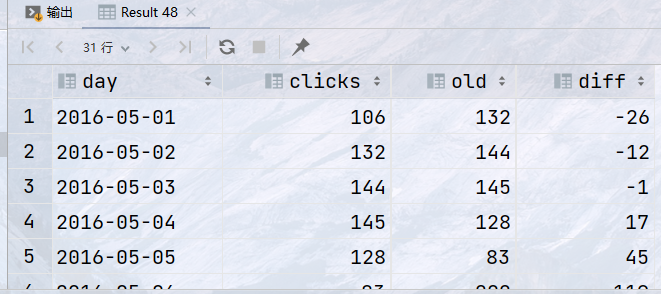
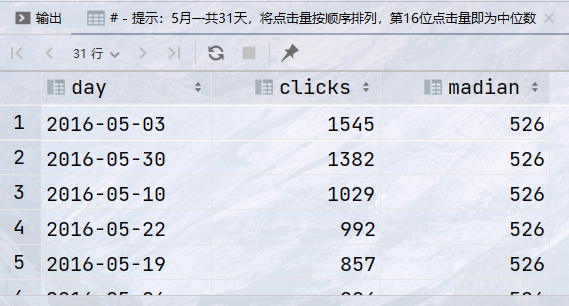
## 需求:统计id为1的网站的点击量,返回如下字段 ## - 日期 day, 点击量 clicks ,5月点击量的中位数 ## - 提示:5月一共31天,将点击量按顺序排列,第16位点击量即为中位数 select day, clicks, nth_value(clicks, 16) over (order by clicks desc rows between unbounded preceding and unbounded following ) as madian from statistics where website_id = 1;
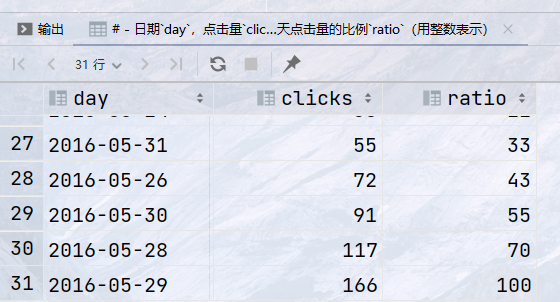
select day, clicks, round(clicks / last_value(clicks) over ( order by clicks rows between unbounded preceding and unbounded following) * 100) as ratio from statistics where website_id = 3;
结果
partition by 与 order by 详解
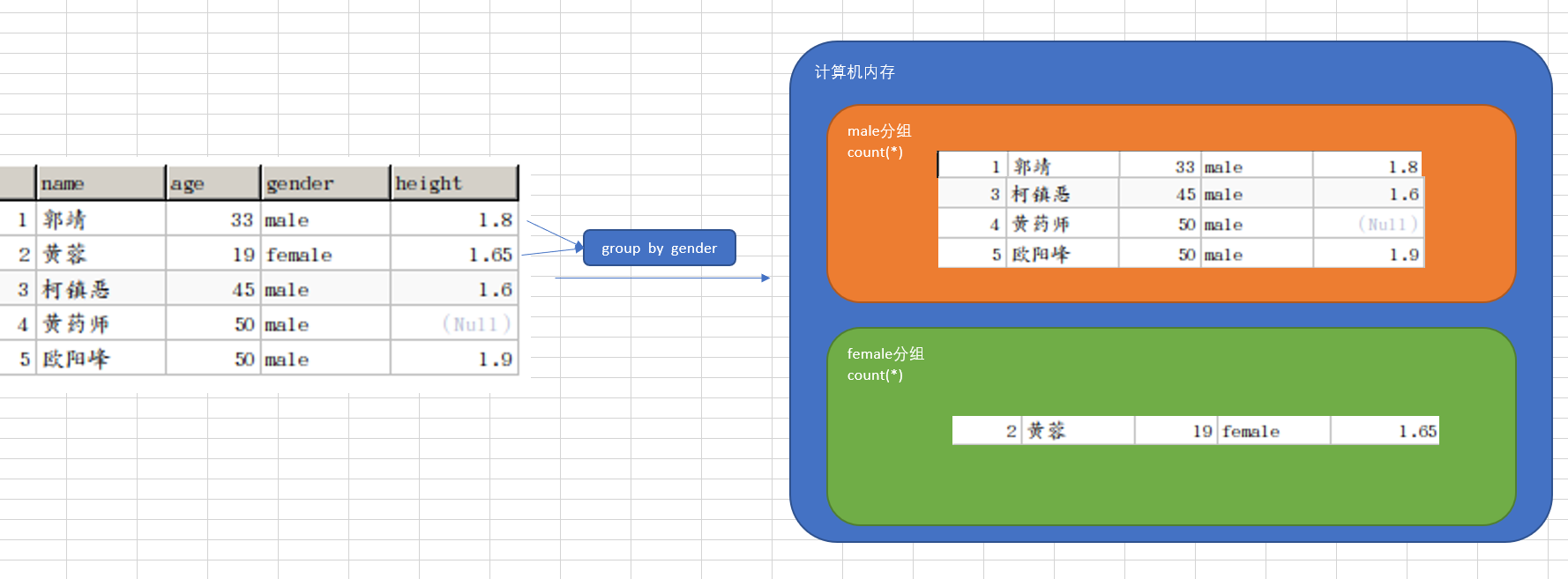
在分组聚合计算时,数据的顺序并不会影响计算结果
如何将PARTITION BY 与排序函数,window frames 和 分析函数组合使用,此时需要将PARTITION BY 与 ORDER BY组合起来,需要注意,PARTITION BY 需要在 ORDER BY前面
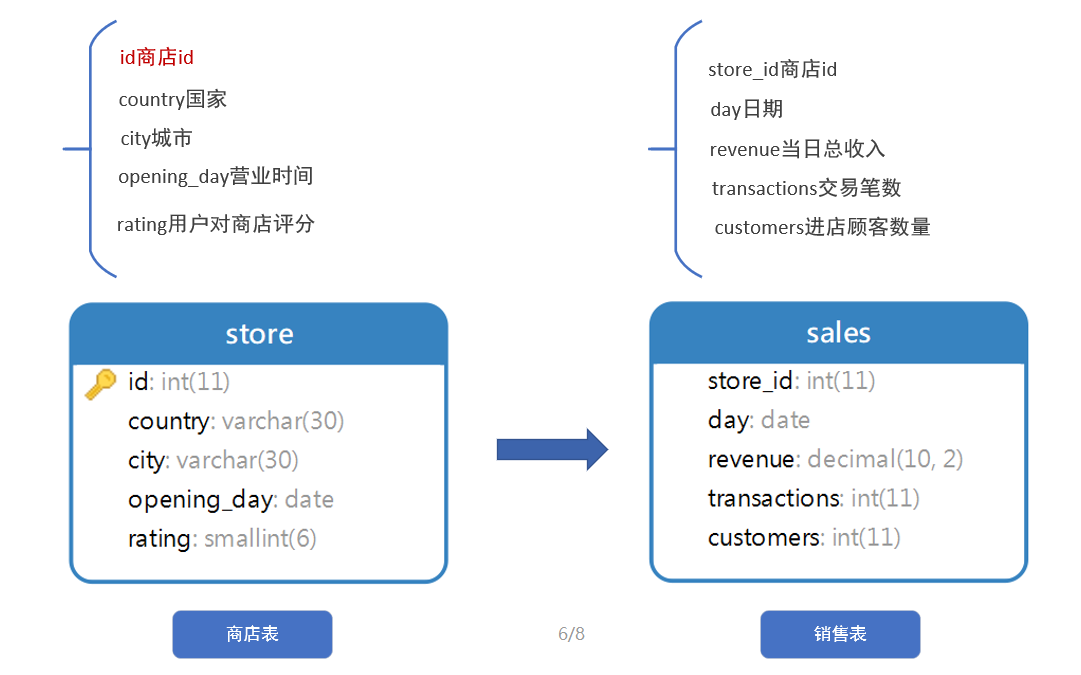
数据表详解:
与常见函数结合
代码
1 2 3 4 5 6
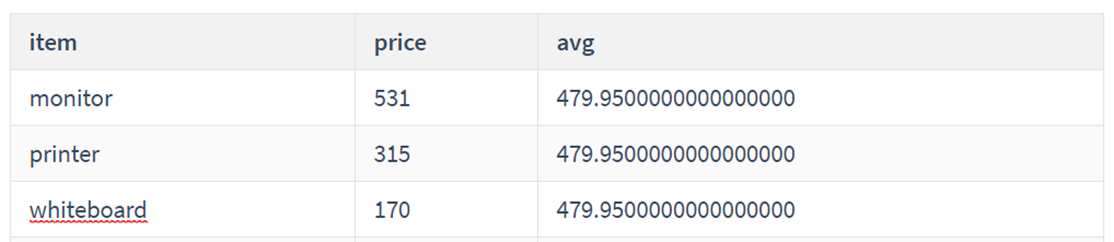
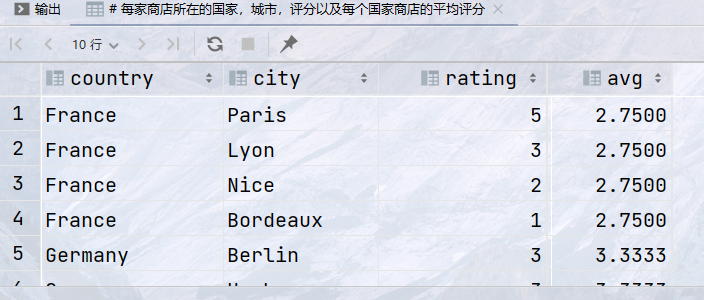
## 每家商店所在的国家,城市,评分以及每个国家商店的平均评分 select country, city, rating, avg(rating) over (partition by country) as avg from store;
结果
代码:
1 2 3 4 5 6
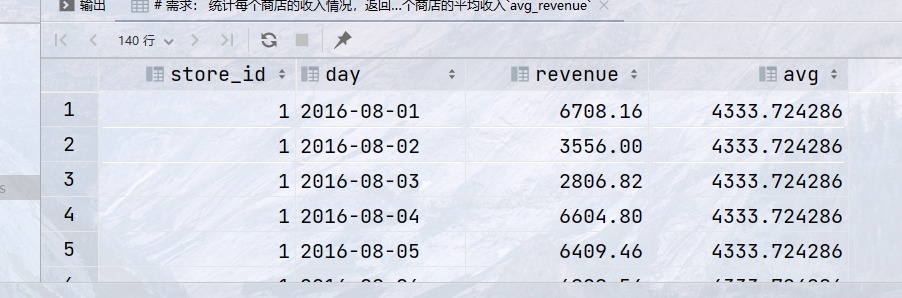
## 需求: 统计每个商店的收入情况,返回字段如下:商店`id` ,日期`day`,收入`revenue`,每个商店的平均收入`avg_revenue` select store_id, day, revenue, avg(revenue) over (partition by store_id) as avg from sales;
结果
rank和partition by 结合
代码
1 2 3 4 5 6
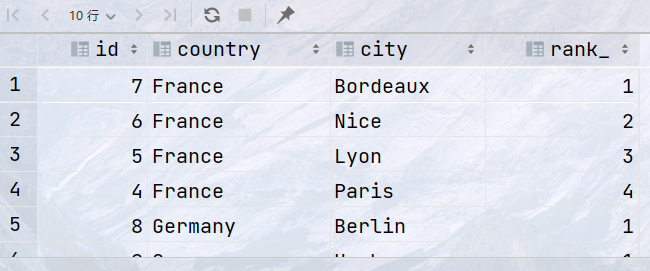
## 用国家分组,对不同国家的商店按评分分别排序 select id, country, city, rank() over (partition by country order by rating ) as rank_ from store;
结果
代码
1 2 3 4 5 6 7 8
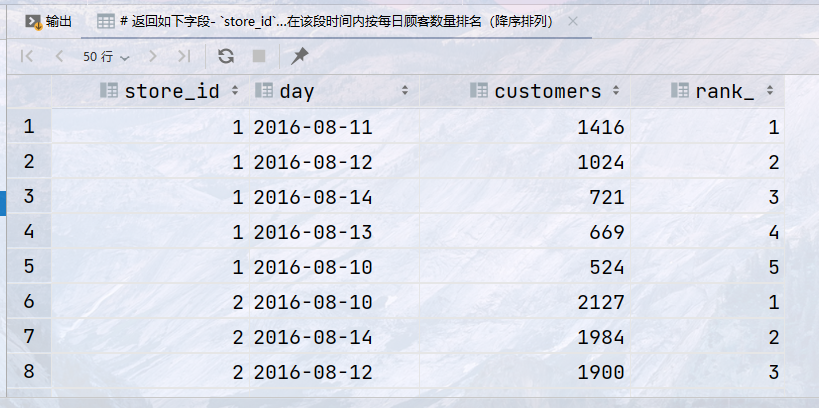
## 需求:统计2016年8月10日至8月14日之间的销售情况, ## 返回如下字段- `store_id`, `day`,顾客数量`customers`, 每个商店在该段时间内按每日顾客数量排名(降序排列) select store_id, day, customers, rank() over (partition by store_id order by customers desc ) as rank_ from sales where day between '2016-08-10' and '2016-08-14';
结果
ntitle和partition by 结合
代码
1 2 3 4 5 6 7 8 9
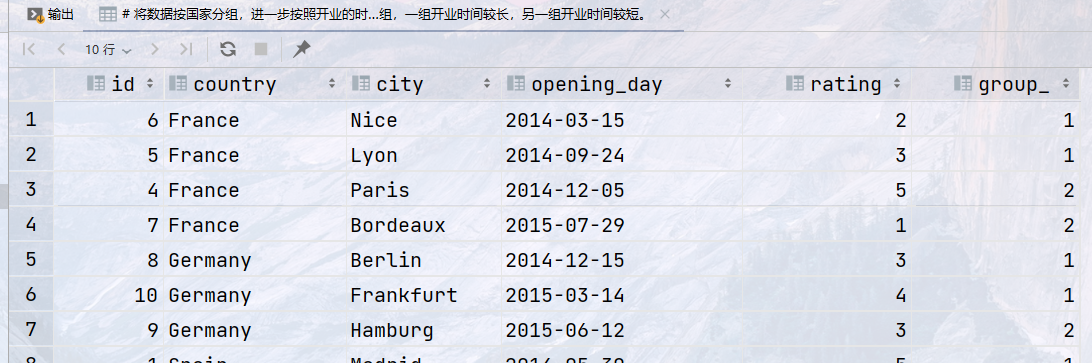
## 将数据按国家分组,进一步按照开业的时间远近划分成两组,一组开业时间较长,另一组开业时间较短。
select id, country, city, opening_day, rating, ntile(2) over (partition by country order by opening_day) as group_ from store;
结果
代码
1 2 3 4 5 6 7 8 9 10 11
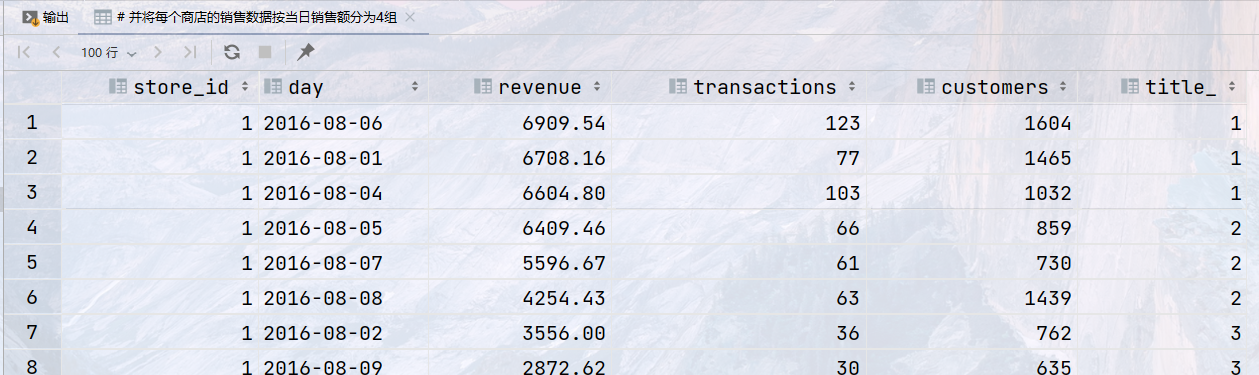
## 统计2016年8月1日至8月10日之间的销售额, ## 查询结果返回:商店ID => `store_id`,日期`day` ,收入`revenue`, ## 并将每个商店的销售数据按当日销售额分为4组 select store_id, day, revenue, transactions, customers, ntile(4) over (partition by store_id order by revenue desc ) as title_ from sales WHERE day BETWEEN '2016-08-01' AND '2016-08-10';
结果
在cte中使用partition by order by
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
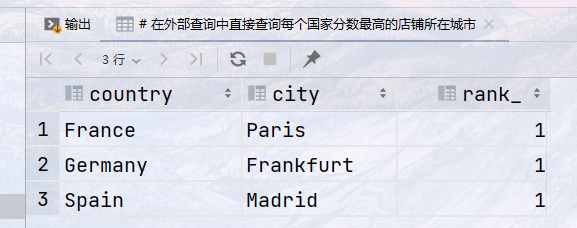
## 通过在CTE中使用窗口函数来获取每个国家/地区按评分的商店排名 ## 在外部查询中直接查询每个国家分数最高的店铺所在城市 with ranking AS ( select id, country, city, opening_day, rating, rank() over (partition by country order by rating desc ) as rank_ from store ) select country, city, rank_ from ranking where rank_ = 1;
结果
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
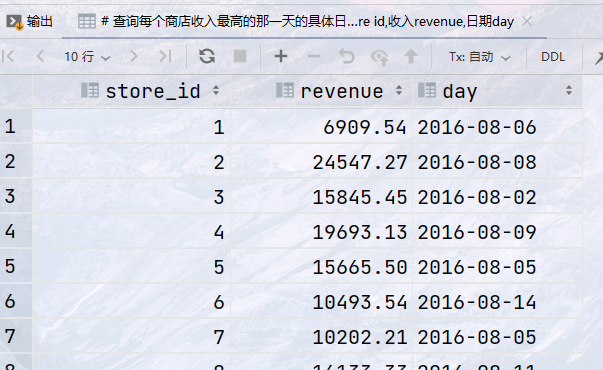
## 查询每个商店收入最高的那一天的具体日期,返回商店store id,收入revenue,日期day with ranking as ( select store_id, day, revenue, transactions, customers, rank() over (partition by store_id order by revenue desc ) as rank_ from sales ) select store_id, revenue, day from ranking where rank_ = 1;
结果
partition by order by 和 window frames组合
代码
1 2 3 4 5 6 7 8 9 10
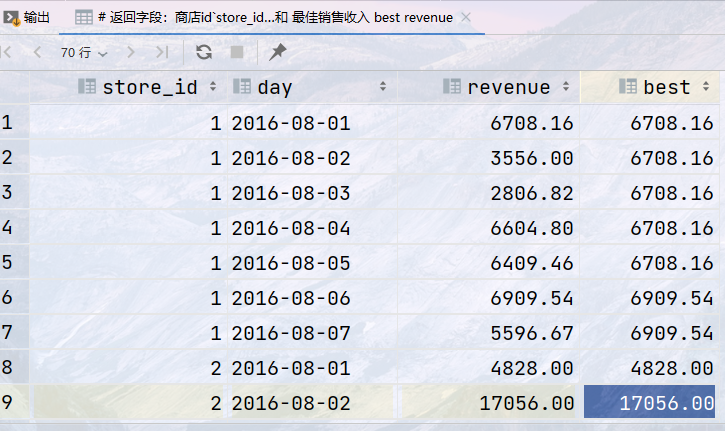
## 分析2016年8月1日到8月7日的销售数据,统计到当前日期为止的单日最高销售收入 ## 返回字段:商店id`store_id`,日期 `day`,销售收入 `revenue` 和 最佳销售收入 best revenue
select store_id, day, revenue, max(revenue) over (partition by store_id order by day rows unbounded preceding) as best
from sales WHERE day BETWEEN '2016-08-01' AND '2016-08-07';
结果
代码
1 2 3 4 5 6 7 8 9 10 11 12
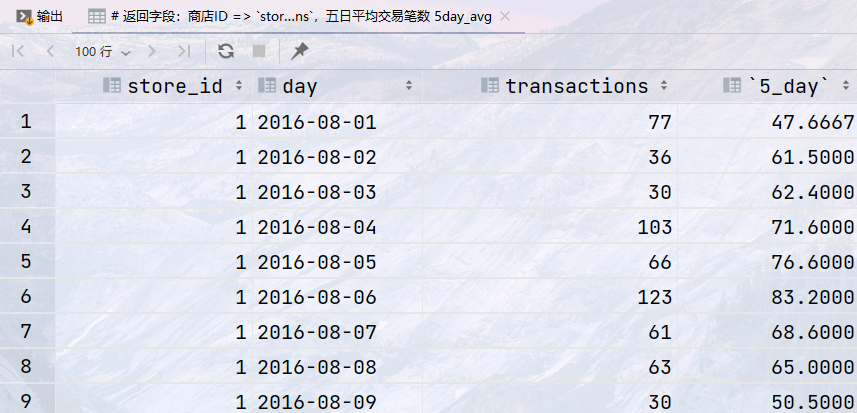
## 统计2016年8月1日至2016年8月10日期间,每间商店的五日平均交易笔数(以当前行为基准,从两天前到两天后共五天) ## 返回字段:商店ID => `store_id`,日期` day`,交易笔数`transactions`,五日平均交易笔数 5day_avg select store_id, day, transactions, avg(transactions) over ( partition by store_id order by day rows between 2 preceding and 2 following ) as 5_day from sales WHERE day BETWEEN '2016-08-01' AND '2016-08-10';
结果
代码
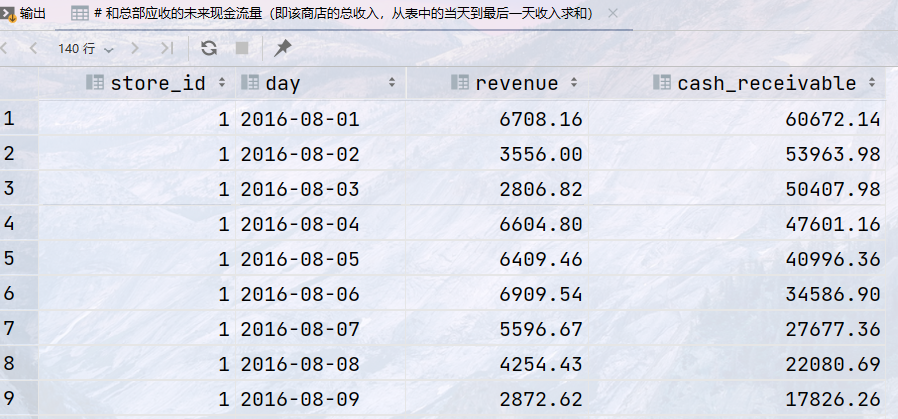
1 2 3 4 5 6 7 8 9 10
#分析销售情况,返回如下内容:商店ID => `store_id`,日期`date`,收入`revenue` ## 和总部应收的未来现金流量(即该商店的总收入,从表中的当天到最后一天收入求和) select store_id, day, revenue, sum(revenue) over (partition by store_id order by day rows between current row and unbounded following ) as cash_receivable from sales;
结果
分析函数 与 partition by order by组合
代码:
1 2 3 4 5 6 7
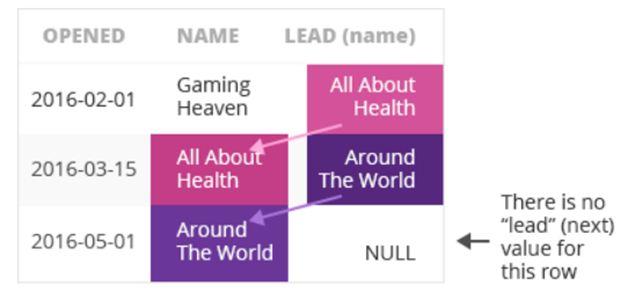
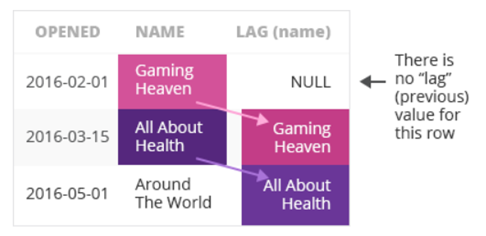
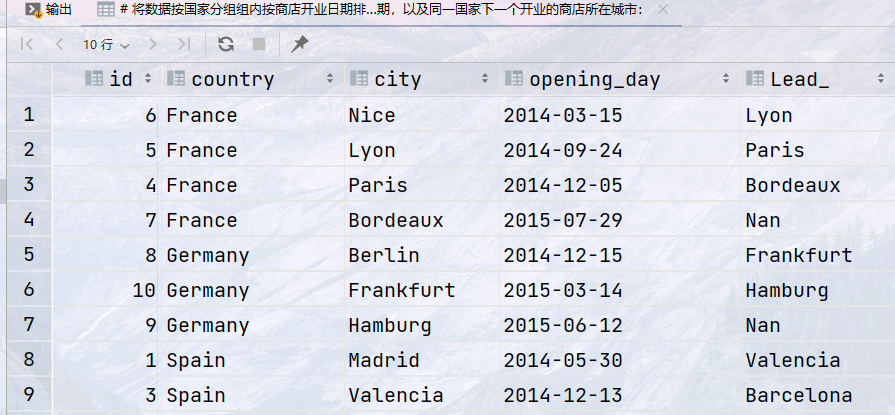
## 将数据按国家分组组内按商店开业日期排序,查询了每个店铺开店的日期,以及同一国家下一个开业的商店所在城市: select id, country, city, opening_day, lead(city,1,'Nan') over (partition by country order by opening_day) AS Lead_ from store;
结果:
代码:
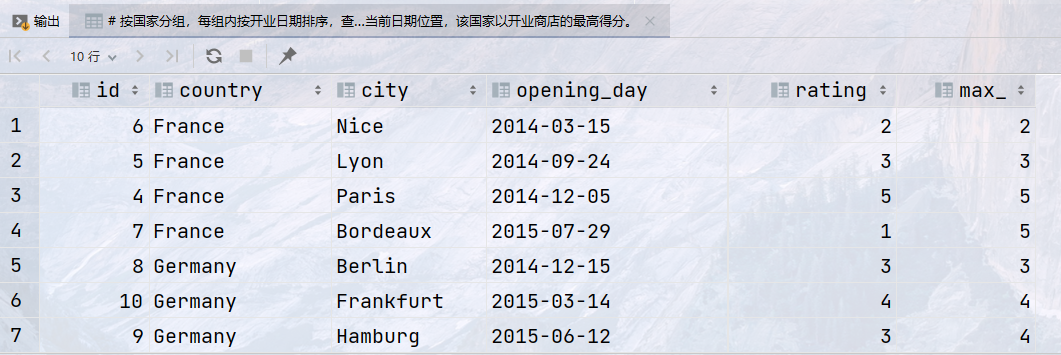
1 2 3 4 5 6 7 8
## 按国家分组,每组内按开业日期排序,查询了到当前日期位置,该国家以开业商店的最高得分。 select id, country, city, opening_day, rating, max(rating) over (partition by country order by opening_day rows unbounded preceding) as max_ from store;
结果:
代码:
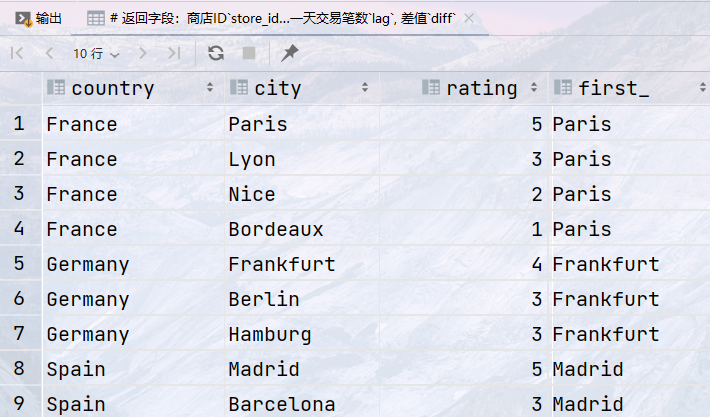
1 2 3 4 5 6
## 返回每个商店的评分,还返回了该店铺所在国家评分最高的商店所在城市 select country, city, rating, first_value(city) over (partition by country order by rating DESC) as first_ from store;
结果:
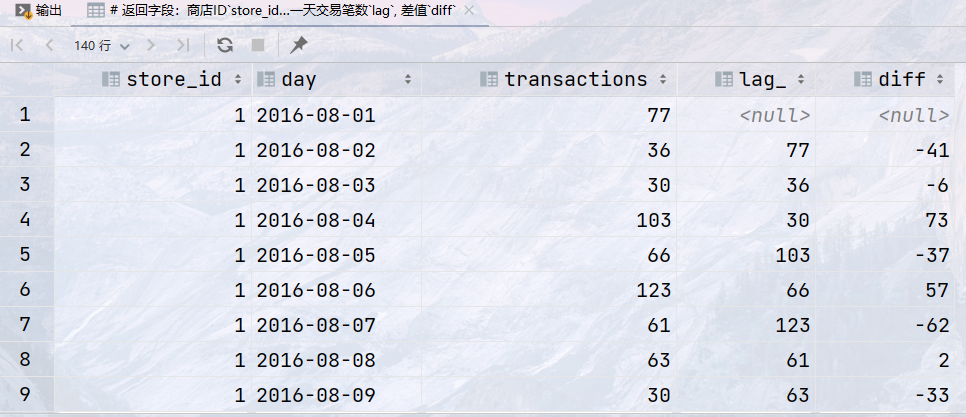
代码:
1 2 3 4 5 6 7 8
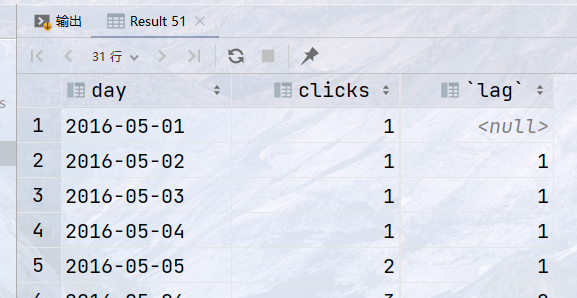
## 需求:统计2016年8月5日 到 2016年8月10日之间,每天的单店交易笔数,前一天交易笔数,前一天和当天的交易笔数的差值 ## 返回字段:商店ID`store_id`, 日期`day`, 交易笔数`transactions`, 前一天交易笔数`lag`, 差值`diff` select store_id, day, transactions, lag(transactions) over (partition by store_id order by day) as lag_, transactions - lag(transactions) over (partition by store_id order by day) as diff from sales;
结果:
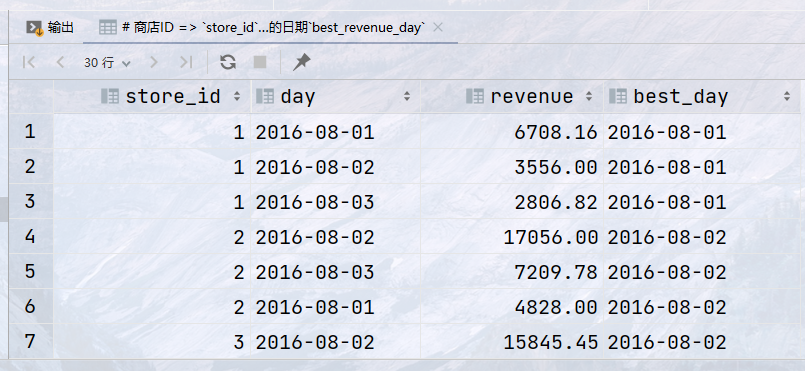
代码:
1 2 3 4 5 6 7 8
## 统计8月1日到8月3日的销售数据找到每个商店在这段时间内销售额最高的一天,返回如下信息: ## 商店ID => `store_id`, 日期 `day`, 当日销售收入 `revenue` , 销售收入最高一天的日期`best_revenue_day` select store_id, day, revenue, first_value(day) over (partition by store_id order by revenue desc ) as best_day from sales where day between '2016-08-01' and '2016-08-03';
结果:
练习表:
代码:
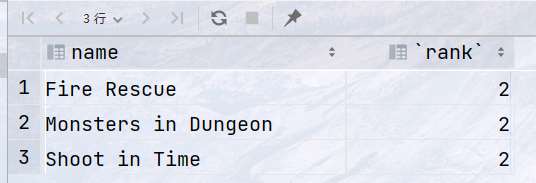
1 2 3 4 5 6 7 8 9 10 11
## 统计每一天,免费维修数量排名第二的手机型号,返回日期 `day` ,手机型号`phone` with ranking as ( select day, phone, dense_rank() over (partition by day order by free_repairs) as max_free from repairs ) select day, phone from ranking where max_free = 2;
结果:
窗口函数避坑指南
不能直接使用窗口函数的子句
我们在第一小节介绍过,where 条件中不能使用窗口函数,原因是sql的执行顺序决定了窗口函数实在where子句之后执行的,具体执行顺序如下: from where group by 聚合函数 having 窗口函数 select distinct union order by offset limit
不能在where子句中使用窗口函数
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## 错误代码写法: SELECT id, final_price FROM auction WHERE final_price > AVG(final_price) OVER();
## 正确代码写法 SELECT id, final_price FROM ( SELECT id, final_price, AVG(final_price) OVER() AS avg_final_price FROM auction) c WHERE final_price > avg_final_price
不能在having子句中使用窗口函数
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## 错误写法 SELECT country, AVG(final_price) FROM auction GROUP BY country HAVING AVG(final_price) > AVG(final_price) OVER ();
## 正确写法 SELECT country, AVG(final_price) FROM auction GROUP BY country HAVING AVG(final_price) > (SELECT AVG(final_price) FROM auction);
不能在group by子句中使用窗口函数
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
## 错误写法 SELECT NTILE(4) OVER(ORDER BY views DESC) AS quartile, MIN(views), MAX(views) FROM auction GROUP BY NTILE(4) OVER(ORDER BY views DESC);
## 正确写法 SELECT quartile, MIN(views), MAX(views) FROM (SELECT views, ntile(4) OVER(ORDER BY views DESC) AS quartile FROM auction) c GROUP BY quartile;
结果:
不能直接使用窗口函数的子句
在order by中使用窗口函数
代码:
1 2 3 4 5 6
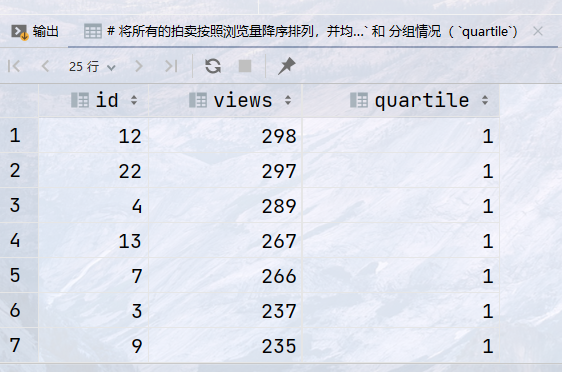
## 将所有的拍卖按照浏览量降序排列,并均分成4组,按照每组编号升序排列,返回字段: `id`, `views` 和 分组情况( `quartile`) select id, views, ntile(4) over (order by views desc ) as quartile from auction order by quartile;
结果:
在group by中使用窗口函数
代码:
1 2 3 4 5 6 7 8 9
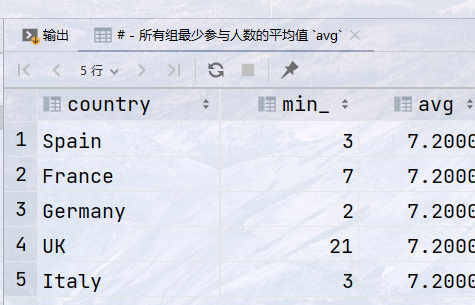
## 需求:将拍卖数据按国家分组,查询如下字段: ## - 国家 `country` ## - 每组最少参与人数 `min` ## - 所有组最少参与人数的平均值 `avg` select country, min(participants)as min_, avg(min(participants)) over()as avg from auction group by country;
结果:
Rank时使用聚合函数
必须在group by后才能使用rank+聚合
代码:
1 2 3 4 5 6
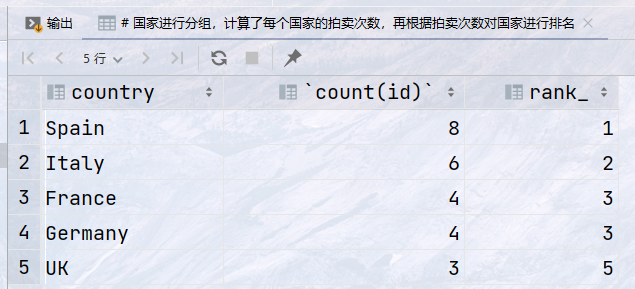
## 国家进行分组,计算了每个国家的拍卖次数,再根据拍卖次数对国家进行排名 select country, count(id), rank() over (order by count(id) desc ) as rank_ from auction group by country;
结果:
代码:
1 2 3 4 5 6 7
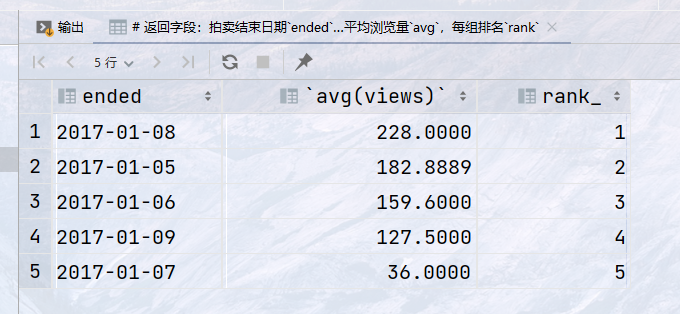
## 按拍卖结束日期`ended`分组,计算每组平均浏览量(`views`),并按平均浏览量对所有组排名返回序号`rank` ## 返回字段:拍卖结束日期`ended`,平均浏览量`avg`,每组排名`rank` select ended, avg(views) as avg_, rank() over (order by avg(views) desc ) as rank_ from auction group by ended;
结果:
利用GROUP BY计算环比
代码:
1 2 3 4 5 6 7 8 9 10
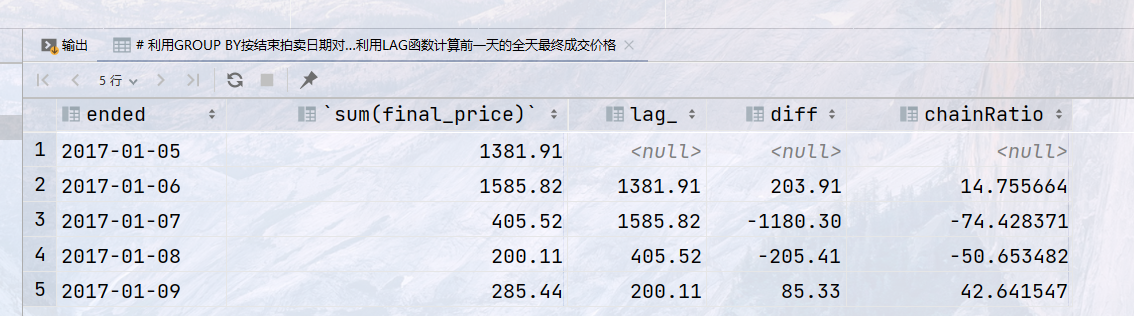
## 利用GROUP BY按结束拍卖日期对所有拍卖进行分组,对每天结束的所有拍卖的最终成交价格求和,利用LAG函数计算前一天的全天最终成交价格 select ended, sum(final_price), lag(sum(final_price)) over (order by ended) as lag_, sum(final_price) - lag(sum(final_price)) over (order by ended) as diff, (sum(final_price) - lag(sum(final_price)) over (order by ended)) / lag(sum(final_price)) over (order by ended) * 100 as chainRatio from auction group by ended order by ended;
结果:
代码:
1 2 3 4 5 6 7 8 9 10 11 12
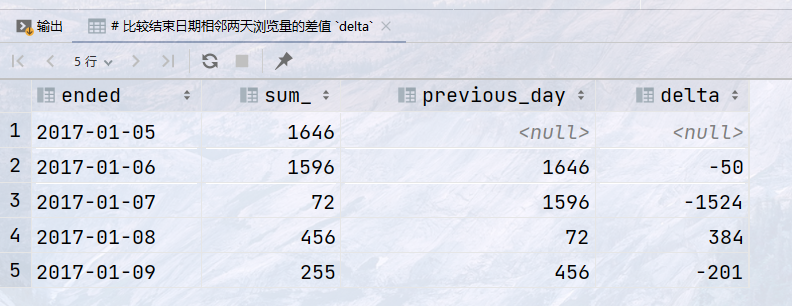
## 需求:按拍卖结束日期`ended`分组分析所有拍卖的浏览数据`views`,返回如下字段: ## 每组的拍卖结束日期`ended` ## 每组的总浏览量 `sum` ## 每组的前一组总浏览量 `previous_day` ## 比较结束日期相邻两天浏览量的差值 `delta` select ended, sum(views) as sum_, lag(sum(views)) over (order by ended) as previous_day, sum(views) - lag(sum(views)) over (order by ended) as delta from auction group by ended;
结果:
对group by分组后的数据使用 partition by
group by 先执行 partition by是与窗口函数一起执行
group by分组后的数据进一步分组(partition by)
代码:
1 2 3 4 5 6 7 8 9 10 11
## 对分组后的数据再进行分组 ## 我们先将所有的数据按照国家country 和拍卖结束时间ended 分组,然后显示了国家名字和拍卖结束日期 ## 接下来SUM(views) AS views_on_day根据 GROUP BY 分组结果(先国家,后日期),对每组的浏览量求和 ## SUM(SUM(views)) OVER(PARTITION BY country) AS views_country 这是一个窗口函数,只对国家进行分组,计算每个国家拍卖的总浏览量 select country, ended, sum(views) as one_day_views, sum(sum(views)) over (partition by country) as views_country from auction group by country,ended order by country,ended;
结果:
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13
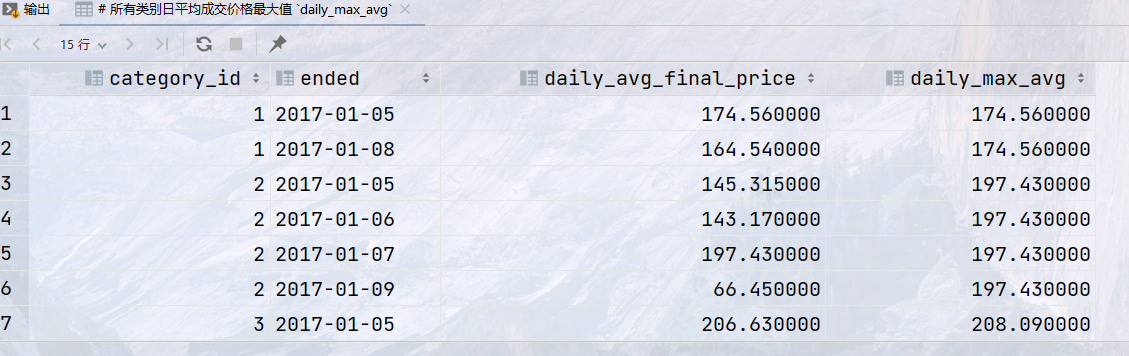
## 将所有数据按照类别`category_id`和拍卖结束日期`ended`分组,返回 ## 类别ID,`category_id` ## 结束日期`ended` ## 当前类别,当日结束的拍卖的平均成交价格 `daily_avg_final_price` ## 所有类别日平均成交价格最大值 `daily_max_avg` select category_id, ended, avg(final_price) as daily_avg_final_price, max(avg(final_price)) over (partition by category_id) as daily_max_avg from auction group by category_id, ended order by category_id, ended;
结果:
窗口函数综合练习
代码:
1 2 3 4 5 6 7 8 9 10
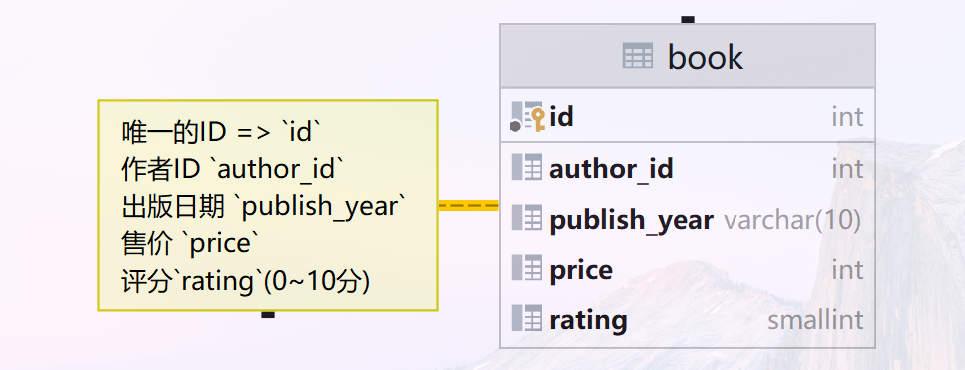
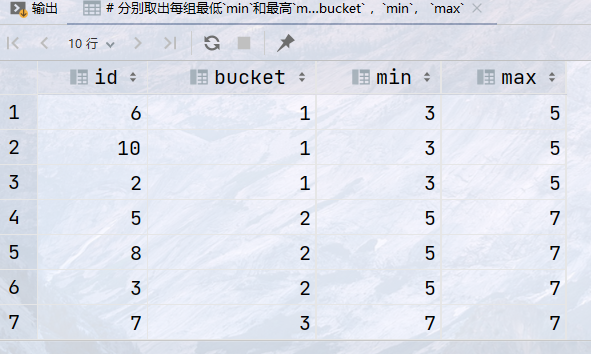
## 把所有的书按照评分从低分到高分平均分成4组,给每组分配一个编号(`bucket`), ## 分别取出每组最低`min`和最高`max`的得分,返回字段:`bucket` ,`min`, `max` select id, bucket, min(rating) over (partition by bucket) as min, max(rating) over (partition by bucket) as max from (select id, rating, ntile(4) over (order by rating) as bucket from book) as rank_;
结果:
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
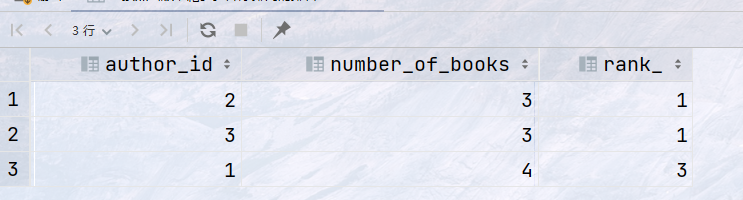
## 统计作者的出版数量,对每一个作者显示: ## 作者id`author_id` ## 这个作者出版了多少本书( `number_of_books`) ## 按照出版书籍多少降序排列的排名`rank` with rank_ as ( select author_id, count(author_id) over (partition by author_id ) as number_of_books from book ) select author_id, number_of_books, rank() over (order by number_of_books) as rank_ from rank_ group by author_id;
结果:
代码:
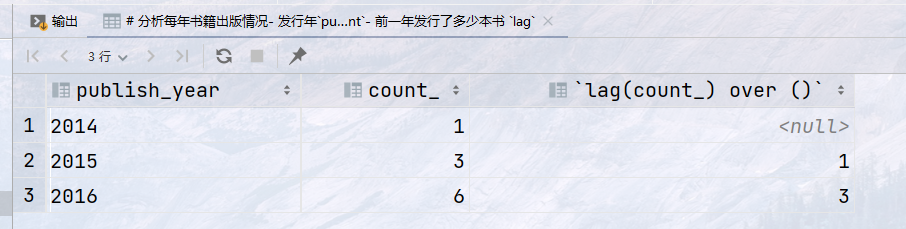
1 2 3 4 5 6 7 8 9 10 11
## 分析每年书籍出版情况- 发行年`publish_year`- 当年发行了多少本书 `count`- 前一年发行了多少本书 `lag` with number as ( select publish_year, count(publish_year) over (partition by publish_year) as count_ from book ) select publish_year, count_, lag(count_) over () from number group by publish_year;