MySQL 基本语句(4个分类)

{mtitle title=”一、DDL 语句”/}
一、DDL 语句(Data Definition Languages,数据定义语言)
这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象。
1.创建数据库
1 | CREATE DATABASE db_name; |
2.删除数据库
1 | DROP DATABASE db_name; |
3.创建表
1 | CREATE TABLE tb_name ( |
column_name 为列的名字, column_type 为列的数据类型, constraints 为列的约束条件。
4.查看表定义
1 | DESC tb_name; |
5.查看创建表的SQL语句
1 | SHOW CREATE TABLE db_name; |
6.删除表
1 | DROP TABLE tb_name |
7.修改表
修改表的数据类型
1 | ALTER TABLE tb_name MODIFY [COLUMN] column_name column_definition [FIRST AFTER column_name]; |
增加表字段
1 | ALTER TABLE tb_name ADD [COLUMN] column_name column_definition [FIRST AFTER column_name]; |
删除表字段
1 | ALTER TABLE tb_name DROP [COLUMN] column_name; |
修改字段名
1 | ALTER TABLE tb_name CHANGE [COLUMN] old_column_name column_name column_definition [FIRST AFTER column_name]; |
修改字段顺序
1 | [FIRST AFTER column_name]; |
修改字段顺序主要是通过 FIRST 和 AFTER,在其后指定字段名则是调整至该字段前一位或后一位,不指定字段名则是调整至最前或者最后。
更改表名
1 | ALTER TABLE tb_name RENAME [TO] new_tb_name; |
{mtitle title=”二、DML 语句”/}
二、DML 语句(Data Manipulation Language,数据操纵语句)
1.插入记录
1 | INSERT INTO tb_name (field1, field2, ..., fieldn) VAULES(value1, value2, ...,valuen); |
可空字段、非空但是含有默认值的字段、自增字段可以不列在字段列表中。
1 | INSERT INTO tb_name VAULES(value1, value2, ...,valuen); |
也可以不指定字段名称,VALUES 顺序和字段排列顺序一致。
1 | INSERT INTO tb_name (field1, field2, ..., fieldn) |
也可以同时插入多行的记录。
2.更新记录
1 | UPDATE tb_name SET field1=value1, field2=value2, ..., fieldn=valuen [WHERE condition]; |
3.更新多个表中的数据
1 | UPDATE tb_name1, tb_name2, ..., tb_namen SET tb_name1.field=value, ..., tb_namen.field=value [WHERE condition]; |
4.删除记录
1 | DELETE FROM tb_name [WHERE condition]; |
5.删除多个表中的数据
1 | DELETE tb_name1, tb_name2, ..., tb_namen FROM tb_name1, tb_name2, ..., tb_namen [WHERE condition]; |
真正要删除的记录在 FROM 前的 tb_name 中,FROM 后的 tb_name 是用于 WHERE 中的条件判断。
6.查询记录
1 | SELECT column_name FROM tb_name; |
查询不重复的记录
在要查询的 column_name 前添加字段 distinct
1 | SELECT distinct column_name FROM tb_name; |
条件查询
1 | SELECT column_name FROM tb_name WHERE condition; |
排序
1 | SELECT * FROM tb_name [WHERE condition] [ORDER BY field1 [DESCASC], field2 [DESCASC], ..., fieldn [DESCACS]]; |
DESC 表示按照字段进行降序排序, ASC 表示升序排序,不指定默认升序排序。
限制
1 | SELECT * FROM tb_name [LIMIT offset_start, row_count]; |
offset_start 表示偏移量, row_conut 表示显示的行数。
1 | SELECT * FROM tb_name [LIMIT row_count]; |
只指定一个参数时,默认偏移量为0。
聚合
很多情况下,需要对一些数据进行汇总。
1 | SELECT [field1, field2, ..., fieldn] function_name |
function_name 表示要做的聚合操作,又称聚合函数。常用的有 sum()、 count(*)、 max() 和 min()。
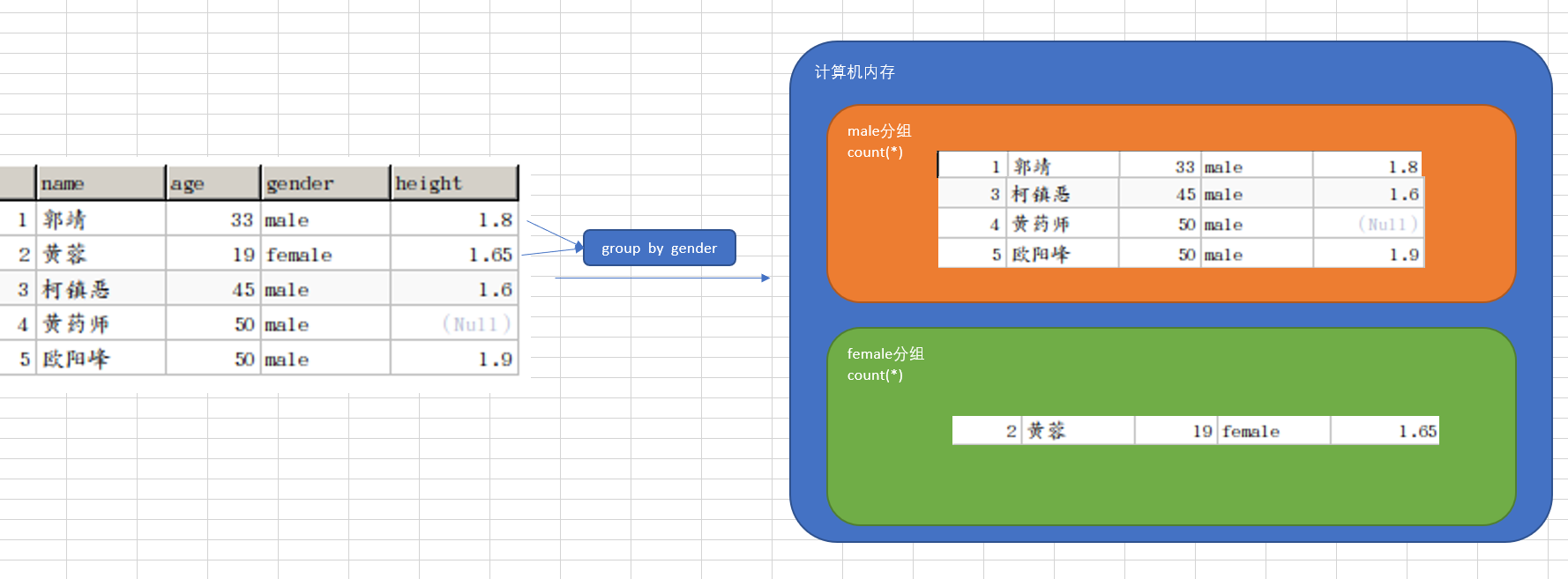
GROUP BY 关键字表示要进行分类聚合的字段。
WITH ROLLUP 表明是否对分类聚合后的结果进行再汇总。
HAVING 关键字表示对分类后的结果再进行条件的过滤。
注意:HAVING 和 WHERE 的区别在于,HAVING 是对聚合后的结果进行条件的过滤,而 WHERE 是对聚合前的记录进行过滤。
表连接
需要同时显示多个表中的字段的时候,通过表连接可以实现,表连接分为内连接和外连接两种。
内连接选出两张表中互相匹配的记录。外连接会选出其它的记录。
内连接
1 | SELECT field1, field2, ...,fieldn FROM tb_name1, tb_name2, ..., tb_namen [WHERE condition]; |
外连接
外连接分为左连接和右连接
左连接:包含左边表中的所有记录,左边表中某些字段的记录在右边表中有没有匹配项会被显示为空。
右连接:包含右边表中的所有记录,右边表中某些字段的记录在左边表中有没有匹配项会被显示为空。
1 | SELECT left_field, right_field FROM left_tb_name |
1 | SELECT left_field, right_field FROM right_tb_name |
子查询
查询的时候,condition 需要的条件是另外一个 SELECT 语句的结果,称为子查询。
子查询的关键字主要包括:IN、 NOT IN、 =、 !=、 EXISTS 和
NOT EXISTS 等。
记录联合
将两个表的数据按照一定的查询条件查询出来后,将结果合并到一起显示出来。关键字是 UNION 和 UNION ALL。
1 | SELECT * FROM tb_name1 [WHERE condition] |
UNION ALL 是表示全部记录,包括了多个查询结果的重复记录。如果希望去掉多个查询结果的重复记录,使用 UNION 关键字。
{mtitle title=”三、DCL 语句”/}
三、DCL 语句(Data Control Language,数据控制语句)
这些语句主要是 DBA 用于管理系统中的对象权限
1.权限控制
1 | GRANT all ON db_name.tb_name TO 'user_name'@'host_name'; |
1 | REVOKE all ON db_name.tb_name FROM 'user_name'@'host_name'; |