Clickhouse物化视图探索Part2
Clickhouse物化视图探索Part2
翻译至ALTINITY博客 原文地址
在之前关于物化视图的博客文章中,我们介绍了一种构建ClickHouse物化视图的方法,该视图使用SummingMergeTree引擎计算总和和计数。SummingMergeTree可以对这两种类型的聚合使用正常的SQL语法。我们还让物化视图定义自动创建数据的底层表。这两种技术都很快,但对生产系统有局限性。
在本文中,我们将展示如何在现有表上创建具有一系列聚合类型的物化视图。这种近似方法适用于需要计算多个简单和的情况。
对于表中有大量到达数据或必须处理模式更改的情况,它也很方便。
使用State Functions 和TO Tables来创建更灵活的视图
在下面的示例中,我们将测量设备的读数。让我们从表定义开始。
1 | CREATE TABLE efun_study.counter ( |
接下来,我们添加足够多的数据,以使查询时间足够慢,足够有趣: 10个设备的10亿行合成数据。
注意: 如果您正在尝试这些方法,那么您只需要在开始时放入一百万行即可。无论数据量如何,这些示例都能正常工作。
1 | INSERT INTO counter |
现在,让我们看一下要定期运行的示例查询。
它总结了整个采样持续时间的所有设备的所有数据。
在这种情况下,这意味着从表格中获得了3.25年的数据,所有数据都在2019年之前。
1 | SELECT |
前面的查询速度很慢,因为它必须读取表中的所有数据才能得到答案。我们想要设计一个能够读取更少数据的物化视图。
事实证明,如果我们定义一个每天汇总数据的视图,ClickHouse将正确地汇总整个时间间隔内的每日总计。
与前面的简单示例不同,我们将自己定义目标表。这样做的优点是表现在是可见的,这使得加载数据和进行模式迁移更加容易。这是目标表定义。
1 | CREATE TABLE counter_daily ( |
表定义引入了一个新的数据类型,称为聚合函数,它保存部分聚合的数据。除了总和或计数以外的聚合需要该类型。
接下来,我们创建相应的物化视图。它从 counter (源表)中进行选择,并在 CREATE 语句中使用特殊的 TO 语法将数据发送到 counter _ daily (目标表)。
如果表具有聚合函数,则 SELECT 语句具有类似于maxState的匹配函数。在详细讨论聚合函数时,我们将介绍这些函数之间的关系。
1 | CREATE MATERIALIZED VIEW counter_daily_mv |
TO关键字允许我们指向目标表,但有一个缺点。ClickHouse不允许将POPULATE关键字与TO一起使用。
若有POPULATE 则在创建视图的过程会将源表已经存在的数据一并导入,类似于 create table … as
若无POPULATE 则物化视图在创建之后没有数据
因此,从物化视图开始,没有数据。
我们将手动加载数据。但我们还将使用一个很好的技巧,使我们能够避免在同时进行活动数据加载的情况下出现问题。
请注意,视图定义有一个WHERE子句。这意味着2019年之前的任何数据都应该被忽略。我们现在有了一种处理数据加载的方法,不会丢失数据。该视图将处理2019年的新数据。
同时,我们可以通过插入加载2018年及之前的旧数据。
让我们通过将新数据加载到计数器表来演示其工作原理。新数据将于2019年开始,并应自动加载到视图中。
1 | INSERT INTO counter |
现在,让我们使用下面的INSERT手动加载较旧的数据。它加载2018年及之前的所有数据。
1 | INSERT INTO counter_daily |
我们终于可以从视图中选择数据了。与目标表和物化视图一样,ClickHouse使用专门的语法从视图中进行选择。
1 | SELECT |
此查询正确地汇总了包括新行在内的所有数据。您可以通过在计数器表上重新运行原始SELECT来检查数学。不同之处在于,物化视图返回数据的速度要快900倍左右。值得学习一些新的语法来实现这一点!!
在这一点上,我们可以回过头来解释底层发生了什么。
聚合函数
聚合函数类似于收集器,允许ClickHouse从分布在多个部分的数据中构建聚合。
下图显示了如何计算平均值。
我们从源表中的一个可选值开始。
物化视图使用avgState函数将数据转换为部分聚合,avgState函数是一种内部结构。最后,在选择数据输出时,应用avgMerge将部分聚集汇总到结果数中。
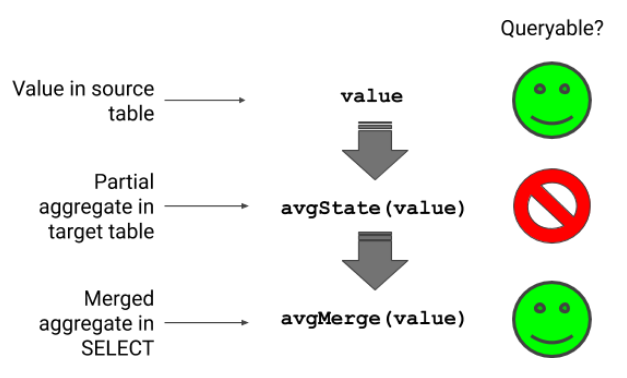
部分聚集体使实质性的视图能够与分布在多个节点上的许多部分的数据一起工作。即使您通过变量更改组,合并功能也可以正确组装聚合。它不仅可以结合简单的平均值,因为它们将缺少缩放每个部分平均值所需的权重,因为它们会增加总数。这种行为具有重要的后果。
还记得上面的时候,我们提到Clickhouse可以使用具有摘要的每日数据的实现视图来回答我们的示例查询吗?这是总体功能如何工作的结果。这意味着我们的日常观点还可以回答有关周,月,年或整个间隔的问题。
Clickhouse在SQL语法中直接暴露部分聚集体有些不寻常,但是他们解决问题的工作方式非常强大。当您设计实质性的视图时,请尝试使用每日摘要之类的技巧来解决单个视图的多个问题。单个视图可以回答很多问题。
物化视图的表引擎
ClickHouse有多个引擎,对物化视图很有用。AggregatingMergeTree引擎仅适用于聚合函数。如果要进行计数或求和,则需要使用目标表中的AggregateFunction数据类型来定义它们。您还需要在view和select语句中使用state和merge函数。例如,要处理计数,您需要在上面的工作示例中使用countState(count)和countMerge(count)。
我们建议SummingMergeTree引擎在物化视图中进行聚合。它可以很好地处理聚合函数。然而,它隐藏了它们的总和和计数,这对于简单的情况很方便。在这种情况下,它不会阻止您使用状态和合并函数;只是你不必这么做。同时,它完成了AggregatingMergeTree所做的一切。
模式更改
数据库模式在生产系统中往往会发生变化,尤其是那些正在积极开发的系统。当使用具有显式目标表的物化视图时,可以相对轻松地管理此类更改。
让我们举一个简单的例子。假设计数器表的名称更改为counter_replicated。应用此更改后,物化视图将无法工作。更糟糕的是,失败将阻止对计数器表的插入。您可以按以下方式处理更改。
1 | -- 在更改模式之前,请删除视图 |
根据模式迁移中的实际步骤,您可能必须解决在更改物化视图定义时出现的丢失数据。正如我们在主要示例中所示,您可以使用过滤条件和手动加载来处理这个问题。
物化视图管道和数据大小
最后,让我们再次看看数据表和物化视图之间的关系。目标表是普通表。您可以从目标表或物化视图中选择数据。没有区别。此外,如果删除物化视图,表仍然存在。正如我们刚才所展示的,您可以通过简单地删除并重新创建视图来对其进行模式更改。如果需要更改目标表本身,请像对任何其他表一样运行ALTER table命令。
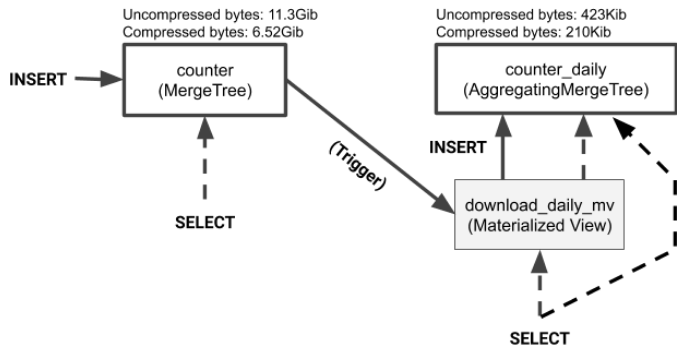
该图还显示了源表和目标表的数据大小。物化视图通常比它们聚合数据的表小得多。这里当然是这样。以下查询显示了此示例的大小差异。
1 | SELECT |
如计算所示,物化视图目标表大约比从中派生物化视图的源数据小30000倍。这种差异大大加快了查询速度。如前所述,当使用物化视图中的数据时,我们的测试查询运行速度快了约900倍。
总结
由于强大的聚合功能以及源表、物化视图和目标表之间的简单关系,ClickHouse物化视图非常灵活。物化视图允许显式目标表这一事实是一个有用的特性,可以简化模式迁移。您还可以通过向视图选择定义添加过滤条件并手动加载丢失的数据来缓解潜在的丢失视图更新。
物化视图还有许多其他方式可以帮助转换数据。我们已经描述了其中的一些问题,例如最后一点查询,并计划在以后的博客上写下其他问题。有关更多信息,请查看我们最近的网络研讨会,题为ClickHouse和物化视图的魔力。我们在这里介绍了几个用例示例。
最后,如果您正在以您认为其他用户感兴趣的方式使用物化视图,请写一篇文章或在当地的ClickHouse会议上演示。我们很乐意在Altinity博客上发布社区用户的内容,并一直在寻找未来聚会的演讲者。如果你有什么想与社区分享的,请告诉我们。





