Clickhouse物化视图探索Part1
翻译至ALTINITY博客 原文地址
Altinity博客的读者知道我们喜欢ClickHouse的物化视图。物化视图可以计算聚合,从Kafka读取数据,实现最后的查询,并重新组织表主索引和排序顺序。除了这些功能能力之外,物化视图还可以在大量节点上很好地扩展,并在大型数据集上工作。它们是ClickHouse的显著特征之一。
和通常的计算一样,强大的能力意味着至少有一点复杂性。这篇由两部分组成的文章通过准确解释物化视图是如何工作的来填补空白,这样即使是初学者也可以有效地使用它们。我们将提供几个详细的示例,您可以根据自己的使用情况进行调整。在此过程中,我们将探索用于创建视图的语法的确切含义,并让您深入了解ClickHouse的底层功能。示例是完全独立的,因此您可以将其复制/粘贴到clickhouse客户端并自己运行。
物化视图的工作原理:计算总和
ClickHouse物化视图自动在表之间转换数据。它们就像触发器,在插入的行上运行查询,并将结果存储在第二个表中。让我们来看一个基本示例。假设我们有一个记录用户下载的表download,如下所示。
1
2
3
4
5
6
7
| CREATE TABLE download (
when DateTime,
userid UInt32,
bytes Float32
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (userid, when);
|
我们希望跟踪每个用户的每日下载。让我们看看如何通过查询实现这一点。首先,我们需要为单个用户向表中添加一些数据。
1
2
3
4
| INSERT INTO download
SELECT now() + number * 60 as when, 25, rand() % 100000000
FROM system.numbers
LIMIT 5000;
|
接下来,让我们运行一个查询来显示该用户的每日下载。随着新用户的添加,这也将正常工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| SELECT
toStartOfDay(when) AS day,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download
GROUP BY userid, day
ORDER BY userid, day;
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2022-07-06 00:00:00 │ 25 │ 977 │ 47523542514 │
│ 2022-07-07 00:00:00 │ 25 │ 1440 │ 71992388333 │
│ 2022-07-08 00:00:00 │ 25 │ 1440 │ 71422268227 │
│ 2022-07-09 00:00:00 │ 25 │ 1143 │ 56765967553 │
└─────────────────────┴────────┴───────────┴─────────────┘
|
我们可以通过每次运行查询以交互方式计算应用程序的这些每日总计,但对于大型表,提前计算它们会更快、更节省资源。因此,最好将结果放在一个单独的表中,该表可以连续跟踪每天每个用户的下载总量。我们可以使用以下物化视图来实现这一点。
1
2
3
4
5
6
7
8
9
10
11
| CREATE MATERIALIZED VIEW download_daily_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day)
POPULATE
AS SELECT
toStartOfDay(when) AS day,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download
GROUP BY userid, day
|
这里有三件重要的事情需要注意。
物化视图定义允许类似于CREATE TABLE的语法,这很有意思,因为该命令实际上将创建一个隐藏的目标表来保存视图数据。我们使用了一个ClickHouse引擎,该引擎旨在简化求和和和计数:SummingMergeTree。它是计算聚合的物化视图的推荐引擎。
视图定义包括关键字POPULATE。这告诉ClickHouse将视图应用于download表中的现有数据,就像它刚刚插入一样。稍后我们将进一步讨论自动填充。
视图定义包括一个SELECT语句,该语句定义了加载视图时如何转换数据。此查询在表中的新数据上运行,以计算每天每个用户ID的下载次数和总字节数。它本质上与我们以交互方式运行的查询相同,只是在这种情况下,结果将放在隐藏的目标表中。我们可以跳过ORDER BY排序,因为视图定义已经提前确保了排序顺序。
现在让我们直接从物化视图中进行查询。
1
2
3
4
5
6
7
8
9
10
11
| select *
from download_daily_mv
order by day,userid
limit 5;
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2022-07-06 00:00:00 │ 25 │ 977 │ 47523542514 │
│ 2022-07-07 00:00:00 │ 25 │ 1440 │ 71992388333 │
│ 2022-07-08 00:00:00 │ 25 │ 1440 │ 71422268227 │
│ 2022-07-09 00:00:00 │ 25 │ 1143 │ 56765967553 │
└─────────────────────┴────────┴───────────┴─────────────┘
|
这给了我们与之前查询完全相同的答案。原因是上面介绍的POPULATE关键字。它确保源表中的现有数据自动加载到视图中。
然而,有一个重要的警告:如果在视图填充时插入新数据,ClickHouse将丢失这些数据。
在本系列的第二部分中,我们将展示如何手动插入数据并避免遗漏数据的问题。
现在,尝试使用其他用户向表中添加更多数据。
1
2
3
4
5
6
7
| insert into download
select
now() +number*60 as when,
22,
rand() % 100000000
from system.numbers
limit 5000;
|
如果您从物化视图中选择,您将看到它现在有用户标识22和25的总计。请注意,插入完成后,新数据立即可用,视图填充完毕。这是ClickHouse物化视图的一个重要功能,使其对实时分析非常有用。
如下是查询和新结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| select *
from download_daily_mv
order by userid,day;
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2022-07-06 00:00:00 │ 22 │ 933 │ 46875607148 │
│ 2022-07-07 00:00:00 │ 22 │ 1440 │ 71080560811 │
│ 2022-07-08 00:00:00 │ 22 │ 1440 │ 70392984070 │
│ 2022-07-09 00:00:00 │ 22 │ 1187 │ 58741840975 │
└─────────────────────┴────────┴───────────┴─────────────┘
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2022-07-06 00:00:00 │ 25 │ 977 │ 47523542514 │
│ 2022-07-07 00:00:00 │ 25 │ 1440 │ 71992388333 │
│ 2022-07-08 00:00:00 │ 25 │ 1440 │ 71422268227 │
│ 2022-07-09 00:00:00 │ 25 │ 1143 │ 56765967553 │
└─────────────────────┴────────┴───────────┴─────────────┘
|
作为练习,您可以对源下载表运行原始查询,以确认它与视图中的总数匹配。
最后一个例子是,让我们使用daily视图按月选择总计。在这种情况下,我们将每日视图视为正常的表,并按月分组,如下所示。我们添加了WITH TOTALS子句,该子句可以方便地打印聚合的总和。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| SELECT
toStartOfMonth(day) AS month,
userid,
sum(downloads),
sum(bytes)
FROM download_daily_mv
GROUP BY userid, month WITH TOTALS
ORDER BY userid, month
┌──────month─┬─userid─┬─sum(downloads)─┬───sum(bytes)─┐
│ 2022-07-01 │ 22 │ 5000 │ 247090993004 │
│ 2022-07-01 │ 25 │ 5000 │ 247704166627 │
└────────────┴────────┴────────────────┴──────────────┘
Totals:
┌──────month─┬─userid─┬─sum(downloads)─┬───sum(bytes)─┐
│ 1970-01-01 │ 0 │ 10000 │ 494795159631 │
└────────────┴────────┴────────────────┴──────────────┘
|
从前面的示例中,我们可以清楚地看到物化视图如何正确地总结源数据中的数据。正如最后一个例子所示,我们甚至可以“总结总结”。那么到底是怎么回事?下图说明了数据的逻辑流。
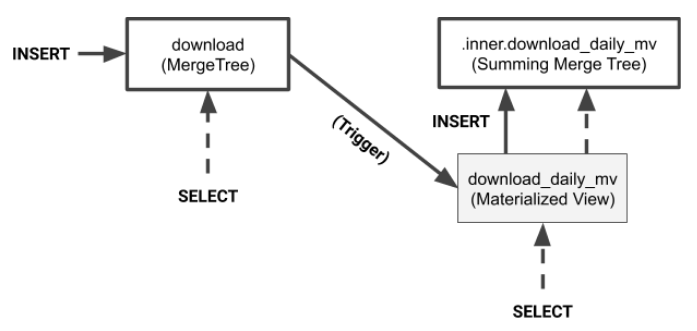
如图所示,源表上INSERT的值被转换并应用于目标表。要重载视图,只需在源表中插入值。
您可以从目标表和物化视图中进行选择。
从中选择物化视图传递给视图自动创建的内部表。
从图表中还有一件重要的事情需要注意。物化视图创建一个具有特殊名称的私有表来保存数据。如果通过键入“DROP TABLE download_daily_mv”删除物化视图,则私有表将消失。
如果需要更改视图,则需要删除它并使用新数据重新创建。
总结
我们刚刚回顾的示例使用SummingMergeTree创建了一个视图来添加每日用户下载。
我们在从物化视图中选择时使用了标准SQL语法。这是SummingMergeTree引擎的特殊功能,仅适用于总和和计数。对于其他类型的聚合,我们需要使用不同的方法。
此外,我们的示例使用POPULATE关键字将现有表数据发布到视图创建的私有目标表中。如果在填充视图时出现新的插入行,则ClickHouse将丢失这些行。当您是唯一使用数据集的人,但对于不断加载数据的生产系统来说,这一限制很容易解决。此外,当视图被删除时,私有表也会消失。这使得很难改变视图以适应源表中的模式更改。
在下一节中,我们将展示如何创建物化视图,以计算其他类型的聚合,如平均值或最大/最小值。我们还将展示如何显式定义目标表,并使用我们自己的SQL语句手动将数据加载到其中。我们还将简要介绍模式迁移。同时,我们希望您喜欢这个简短的介绍,并发现示例很有用。





