大数据_ZooKeeper
Apache Zookeeper
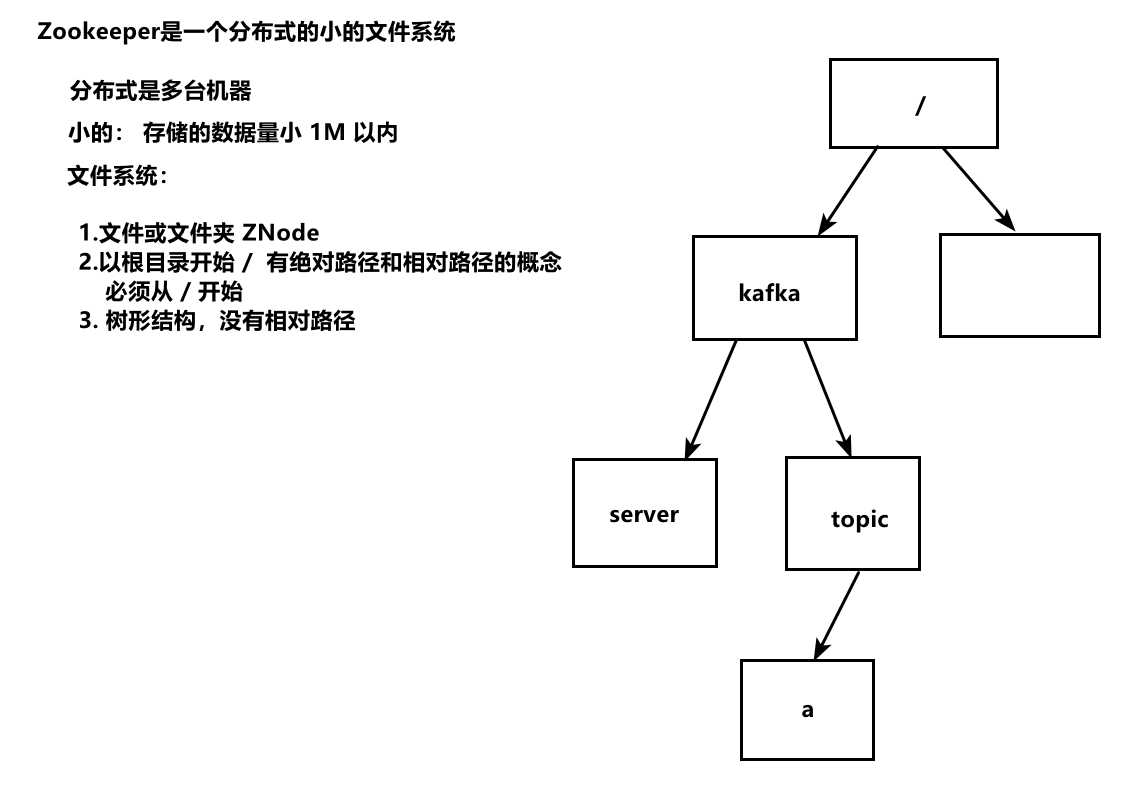
Zookeeper 基础概念
- 是一个分布式的协调服务软件(distributed coordination)。
1 | 分布式:多台机器的环境。 |
- zookeeper的本质:分布式的小文件存储系统
- 存储系统:存储数据、存储文件 目录树结构
- 小文件:上面存储的数据有大小限制 1M
- 分布式:可以部署在多台机器上运行,对比单机来理解。
- 问题:zk这个存储系统和我们常见的存储系统不一样。基于这些不一样产生了很多应用。
- zookeeper是一个标准的主从架构集群。
1
2
3
4主角色
从角色
主从各司其职 共同配合 对外提供服务。
zookeeper最重要的特性:全局数据一致性。
事务(transaction):通俗理解 多个操作组成一个事务,要么一起成功,要么一起失败,不会存在中间的状态。如果中间失败了要进行回滚操作。 主从一致性: Master 主节点、 Follower 从节点,主节点负责管理集群,事务操作(增删改),从节点负责事务操作的转化和非事务操作(读)。
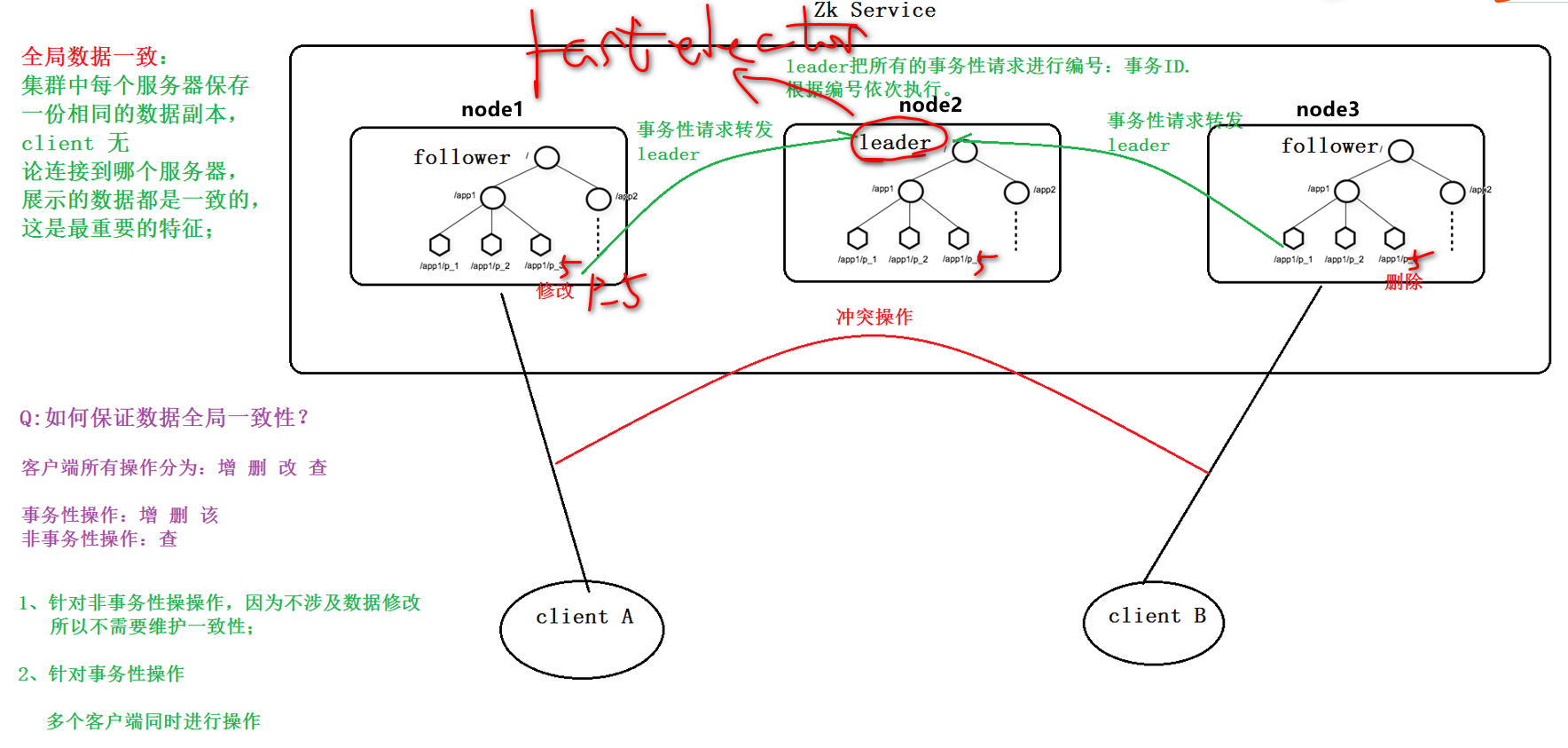
zookeeper集群角色
zk是标准的主从架构,只不过为了扩大集群的读写能力,同时又不增加选举复杂度,又提供了观察者角色。 参考资料——Zookeeper架构FastLeaderElection机制详解
- 主角色 leader
1
事务性请求的唯一调度和处理者
- 从角色 follower
1
2处理非事务性操作 转发事务性操作给leader
参与zk内部选举机制 - 观察者角色 Observer
1
2
3
4处理非事务性操作 转发事务性操作给leader
不参与zk内部选举机制
通俗话:是一群被剥夺政治权利终身的follower。
Zookeeper集群的搭建
- zk集群在搭建部署的时候,通常选择2n+1奇数台。底层 Paxos 算法支持(过半成功)。
- zk部署之前,保证服务器基础环境正常、JDK成功安装。
1
2
3
4scp -r /export/server/jdk1.8.0_65/ root@node3:/export/server/
scp /etc/profile root@node2:/etc/
source /etc/profile- 服务器基础环境
1
2
3
4
5
6IP
主机名
hosts映射
防火墙关闭
时间同步
ssh免密登录- JDK环境
1
2jdk1.8
配置好环境变量 - zk具体安装部署(选择node1安装 scp给其他节点)
- 安装包status
1
zookeeper-3.4.6.tar.gz
- 上传解压重命名
1
2
3
4cd /export/server
tar zxvf zookeeper-3.4.6.tar.gz
mv zookeeper-3.4.6/ zookeeper- 修改配置文件
- zoo.cfg
1
2
3
4
5
6
7
8
9
10
11
12zk默认加载的配置文件是zoo.cfg 因此需要针对模板进行修改。保证名字正确。
cd zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改
dataDir=/export/data/zkdata
文件最后添加 2888心跳端口 3888选举端口
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888 - myid
1
2
3
4在每台机器的dataDir指定的目录下创建一个文件 名字叫做myid
myid里面的数字就是该台机器上server编号。server.N N的数字就是编号
[root@node1 conf]# mkdir -p /export/data/zkdata
[root@node1 conf]# echo 1 >/export/data/zkdata/myid - 把安装包同步到其他节点上
1
2
3cd /export/server
scp -r zookeeper/ node2:$PWD
scp -r zookeeper/ node3:$PWD- 创建其他机器上myid和datadir目录
1
2
3
4
5[root@node2 ~]# mkdir -p /export/data/zkdata
[root@node2 ~]# echo 2 > /export/data/zkdata/myid
[root@node3 ~]# mkdir -p /export/data/zkdata
[root@node3 ~]# echo 3 > /export/data/zkdata/myid - zk集群的启动
- 每台机器上单独启动服务
1
2
3
4
5
6
7
8
9在哪个目录执行启动命令 默认启动日志就生成当前路径下 叫做zookeeper.out
/export/server/zookeeper/bin/zkServer.sh startstopstatus
3台机器启动完毕之后 可以使用status查看角色是否正常。
还可以使用jps命令查看zk进程是否启动。
[root@node3 ~]# jps
2034 Jps
1980 QuorumPeerMain #看我,我就是zk的java进程- 扩展:编写shell脚本 一键脚本启动。
- 本质:在node1机器上执行shell脚本,由shell程序通过ssh免密登录到各个机器上帮助执行命令。
- 一键关闭脚本
1
2
3
4
5
6
7
8[root@node1 ~]# vim stopZk.sh
!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "/export/server/zookeeper/bin/zkServer.sh stop"
done- 一键启动脚本
1
2
3
4
5
6
7
8[root@node1 ~]# vim startZk.sh
!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start"
done- 注意:关闭java进程时候 根据进程号 直接杀死即可就可以关闭。启动java进程的时候 需要JDK。
- shell程序ssh登录的时候不会自动加载/etc/profile 需要shell程序中自己加载。
- 作业:尝试使用一个脚本 实现zookeeper的启动、关闭、状态查看。
Zookeeper的数据模型
- Znode的介绍
- zk的操作
- 第一种客户端:自带shell客户端
1
2
3
4
5
6
7/export/server/zookeeper/bin/zkCli.sh -server ip
如果不加-server 参数 默认去连接本机的zk服务 localhost:2181
如果指定-server 参数 就去连接指定机器上的zk服务
退出客户端端 ctrl+c - 基本操作
- 创建
- 查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[zk: node2(CONNECTED) 28] ls /itcast #查看指定路径下有哪些节点
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 29] get /
zookeeper itcast
[zk: node2(CONNECTED) 29] get /itcast #获取znode的数据和stat属性信息
1111
cZxid = 0x200000003 #创建事务ID
ctime = Fri May 21 16:20:37 CST 2021 #创建的时间
mZxid = 0x200000003 #上次修改时事务ID
mtime = Fri May 21 16:20:37 CST 2021 #上次修改的时间
pZxid = 0x200000009
cversion = 3
dataVersion = 0 #数据版本号 只要有变化 就自动+1
aclVersion = 0
ephemeralOwner = 0x0 #如果为0 表示永久节点 如果是sessionID数字 表示临时节点
dataLength = 4 #数据长度
numChildren = 3 #子节点个数 
- 更新节点
1
set path data
- 删除节点
1
2
3
4
5
6[zk: node2(CONNECTED) 43] ls /itcast
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 44] delete /itcast/bbbb0000000002
[zk: node2(CONNECTED) 45] delete /itcast
Node not empty: /itcast
[zk: node2(CONNECTED) 46] rmr /itcast #递归删除 - quota限制 软性限制
- 限制某个节点下面可以创建几个子节点 数据大小。
- 超过限制,zk不会强制禁止操作 而是在日志中给出warn警告提示。
1
2
3
4
5
6
7[zk: node2(CONNECTED) 47] create /itheima 111
Created /itheima
[zk: node2(CONNECTED) 49] listquota /itheima #查看限制
absolute path is /zookeeper/quota/itheima/zookeeper_limits
quota for /itheima does not exist.
2021-05-21 16:54:42,697 [myid:3] + WARN [CommitProcessor:3:DataTree@388] + Quota exceeded: /itheima count=6 limit=3
Zookeeper监听机制Watch
- 监听机制
- 监听实现需要几步?
1
2
3
4
51、设置监听
2、执行监听
3、事件发生,触发监听 通知给设置监听的 回调callback- zk中的监听是什么?
- 谁监听谁?
1
客户端监听zk服务
- 监听什么事?
1
监听zk上目录树znode的变化情况。 znode增加了 删除了 增加子节点了 不见了
- zk中监听实现步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
151、设置监听 然后zk服务执行监听
ls path [watch]
没有watch 没有监听 就是查看目录下子节点个数
有watch 有监听 设置监听子节点是否有变化
get path [watch]
监听节点数据是否变化
e.g: get /itheima watch
2、触发监听
set /itheima 2222 #修改了被监听的节点数据 触发监听
3、回调通知客户端
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/itheima- zk的监听特性
- 先注册 再触发
- 一次性的监听
- 异步通知
- 通知是使用event事件来封装的
1
2
3
4state:SyncConnected type:NodeDataChanged path:/itheima
type:发生了什么
path:哪里发生的 - zk中监听类型
- 连接状态事件监听 系统自动触发 用户如果不关心可以忽略不计
- 上述所讲的是用户自定义监听 主要监听zk目录树的变化 这类监听必须先注册 再监听。
- 总结:zk的很多功能都是基于这个特殊文件系统而来的。
- 特殊1:znode有临时的特性。
- 特殊2:znode有序列化的特性。顺序
- 特殊3:zk有监听机制 可以满足客户端去监听zk的变化。
- 特殊4:在非序列化节点下,路径是唯一的。不能重名。
小结
1 | 查看Znode的 /tmp 节点的内容 data |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Pandolar's Blog!

评论




