ElasticSearch学习03
ElasticSearch学习03
logstash插件简单使用
grok插件
Grok 是 Logstash 最重要的插件。使用之前一定学会正则表达式,可以在 grok 里预定义好命名正则表达式,在之后(grok参数或者其他正则表达式里)引用它。
语法格式
grok的提取字符串内容的语法其实就是在正则表达式基础之上进行封装,Logstash grok内置了120种默认表达式,解决很多日常需求,不需要重头编写复杂的正则表达式。
grok表达式语法:
%{模式名:自定义字段名}
- 模式名 - 指的就是预先定义好的正则表达式的别名,例如:IP 可以匹配ip内容。
- 自定义字段名 - 通过模式匹配到内容后,将内容保存到这个自定义的字段中
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
解释就是
- %{IP:client} - 匹配IP内容,结果保存到client字段
- %{WORD:method} - 匹配非空字符串内容,结果保存到method字段
- %{URIPATHPARAM:request} - 匹配url路径,结果保存到request字段
- %{NUMBER:bytes} - 匹配数字,结果保存到bytes字段
插件参数
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| match | hash | {} | 定义grok的表达式,格式: message => “表达式” |
| patterns_dir | array | [] | 自定义模式配置文件的路径,支持多个路径,例子:[“/opt/logstash/patterns”, “/opt/logstash/extra_patterns”] |
内置模式
| 表达式标识 | 名称 | 详情 | 匹配例子 |
|---|---|---|---|
| USERNAME 或 USER | 用户名 | 由数字、大小写及特殊字符(._-)组成的字符串 | 1234、Bob、Alex.Wong |
| EMAILLOCALPART | 用户名 | 首位由大小写字母组成,其他位由数字、大小写及特殊字符(_.+-=:)组成的字符串。注意,国内的QQ纯数字邮箱账号是无法匹配的,需要修改正则 | windcoder、windcoder_com、abc-123 |
| EMAILADDRESS | 电子邮件 | windcoder@abc.com、windcoder_com@gmail.com、abc-123@163.com | |
| HTTPDUSER | Apache服务器的用户 | 可以是EMAILADDRESS或USERNAME | |
| INT | 整数 | 包括0和正负整数 | 0、-123、43987 |
| BASE10NUM 或 NUMBER | 十进制数字 | 包括整数和小数 | 0、18、5.23 |
| BASE16NUM | 十六进制数字 | 整数 | 0x0045fa2d、-0x3F8709 |
| WORD | 字符串 | 包括数字和大小写字母 | String、3529345、ILoveYou |
| NOTSPACE | 不带任何空格的字符串 | ||
| SPACE | 空格字符串 | ||
| QUOTEDSTRING 或 QS | 带引号的字符串 | “This is an apple”、’What is your name?’ | |
| UUID | 标准UUID | 550E8400-E29B-11D4-A716-446655440000 | |
| MAC | MAC地址 | 可以是Cisco设备里的MAC地址,也可以是通用或者Windows系统的MAC地址 | |
| IP | IP地址 | IPv4或IPv6地址 | 127.0.0.1、FE80:0000:0000:0000:AAAA:0000:00C2:0002 |
| HOSTNAME | IP或者主机名称 | ||
| HOSTPORT | 主机名(IP)+端口 | 127.0.0.1:3306、api.windcoder.com:8000 | |
| PATH | 路径 | Unix系统或者Windows系统里的路径格式 | /usr/local/nginx/sbin/nginx、c:\windows\system32\clr.exe |
| URIPROTO | URI协议 | http、ftp | |
| URIHOST | URI主机 | windcoder.com、10.0.0.1:22 | |
| URIPATH | URI路径 | //windcoder.com/abc/、/api.php | |
| URIPARAM | URI里的GET参数 | ?a=1&b=2&c=3 | |
| URIPATHPARAM | URI路径+GET参数 | /windcoder.com/abc/api.php?a=1&b=2&c=3 | |
| URI | 完整的URI | https://windcoder.com/abc/api.php?a=1&b=2&c=3 | |
| LOGLEVEL | Log表达式 | Log表达式 | Alert、alert、ALERT、Error |
| 表达式标识 | 名称 | 匹配例子 |
|---|---|---|
| MONTH | 月份名称 | Jan、January |
| MONTHNUM | 月份数字 | 03、9、12 |
| MONTHDAY | 日期数字 | 03、9、31 |
| DAY | 星期几名称 | Mon、Monday |
| YEAR | 年份数字 | |
| HOUR | 小时数字 | |
| MINUTE | 分钟数字 | |
| SECOND | 秒数字 | |
| TIME | 时间 | 00:01:23 |
| DATE_US | 美国时间 | 10-01-1892、10/01/1892/ |
| DATE_EU | 欧洲日期格式 | 01-10-1892、01/10/1882、01.10.1892 |
| ISO8601_TIMEZONE | ISO8601时间格式 | +10:23、-1023 |
| TIMESTAMP_ISO8601 | ISO8601时间戳格式 | 2016-07-03T00:34:06+08:00 |
| DATE | 日期 | 美国日期%{DATE_US}或者欧洲日期%{DATE_EU} | |
| DATESTAMP | 完整日期+时间 | 07-03-2016 00:34:06 |
| HTTPDATE | http默认日期格式 | 03/Jul/2016:00:36:53 +0800 |
详细用法可以查看sqian-blog/logstash插件-grok使用方法
自定义模式
如果grok内置的模式无法满足需求,也可以自定义模式。
模式定义语法:
1 | NAME PATTERN |
说明:
- NAME - 模式名
- PATTERN - 表达式,包括正则表达式和logstash变量。
例:
配置文件路径:/opt/logstash/patterns ,文件内容如下
1 | test_patterns \d+ |
提示:自定义模式配置文件路径,可以根据项目情况自定义即可
在logstash配置文件中引用自定义表达式
1 | filter { |
基本使用
例子:
从Jun 8 09:19:54 node1 systemd-logind: Removed session 38.
取出→日期Jun 8 09:19:54+主机node1+进程systemd-logind+信息Removed session 38.
我们需要编写正则表达式进行提取
时间:
\w+.*\d{2}:\d{2}:\d{2}写在里面就是
(?<time>\w+.*\d{2}:\d{2}:\d{2})主机:
因为取出前一个之后会直接从后面开始取, 所以直接
\S+其他以此类推
然后将所有小表达式拼接成一个大的表达式
(?<time>\w+.*\d{2}:\d{2}:\d{2}) (?<hostname>\S+) (?<sys>\S+): (?<msg>.*)
完整配置文件写法就是:
1 | input { |
Run
./bin/logstash -f ./config/file_grok_stdout_01.conf
输出为
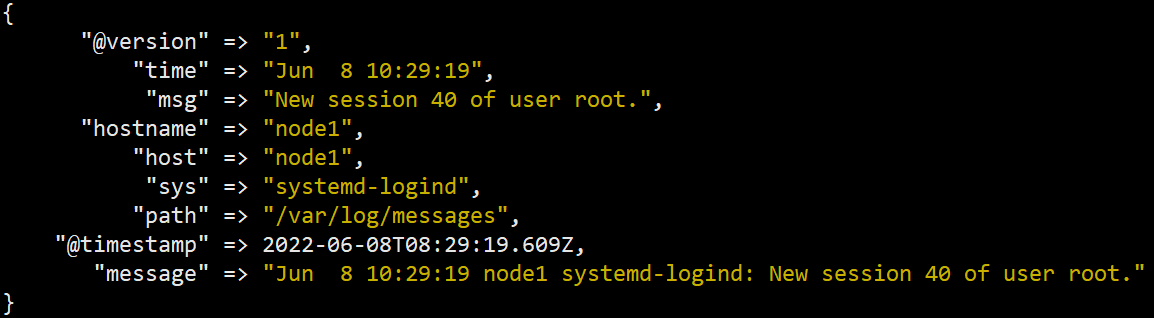
GrokDebugger
Kibana支持在线调试grok
data插件
不错的参考文章Date Filter 插件
基本介绍
data插件用于分析字段中的日期,然后将该日期或时间戳用作事件的 logstash 时间戳。
例如,系统日志事件通常具有时间戳: "Apr 17 09:32:01"
我们可以把他解析成MMM dd HH:mm:ss
基本格式
如果是单个格式可以写成
1 | filter { |
如果是多个时间格式
1 | filter { |
基本使用
例子
书接上回
然后我们将time字段转换为ES的标准时间格式并且命名为@timestamp_02
1 | input { |
结果图在跑完mutate插件一起放
mutate插件
基本介绍
mutate插件可以重命名、移除、替换和修改事件中的字段, 平时使用也较多.
mutate有很多处理方法, 按照执行顺序排:
- coerce
- rename
- update
- replace
- convert
- gsub
- uppercase
- capitalize
- lowercase
- strip
- remove
- split
- join
- merge
- copy
基本格式
1 | filter { |
由于方法较多且功能强大, 可以直接参考上面的官方文档
基本使用
书接上回
例子
1 | input { |
效果图
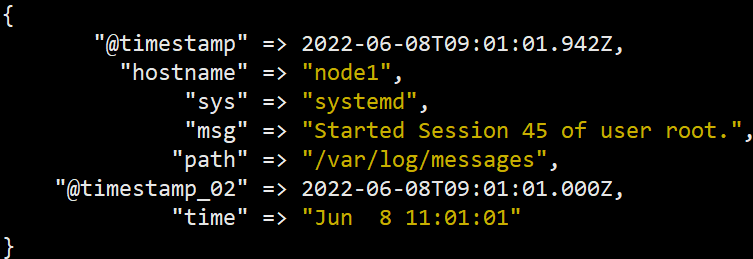
执行顺序就是先grok再date后mutate, 以此类推
写入ES
本次测试我们使用logstash从Linux系统的日志文件读取数据到ES里面, 使用到了生命周期和索引模板等
设置生命周期
1 | PUT _ilm/policy/efun_policy |
机翻
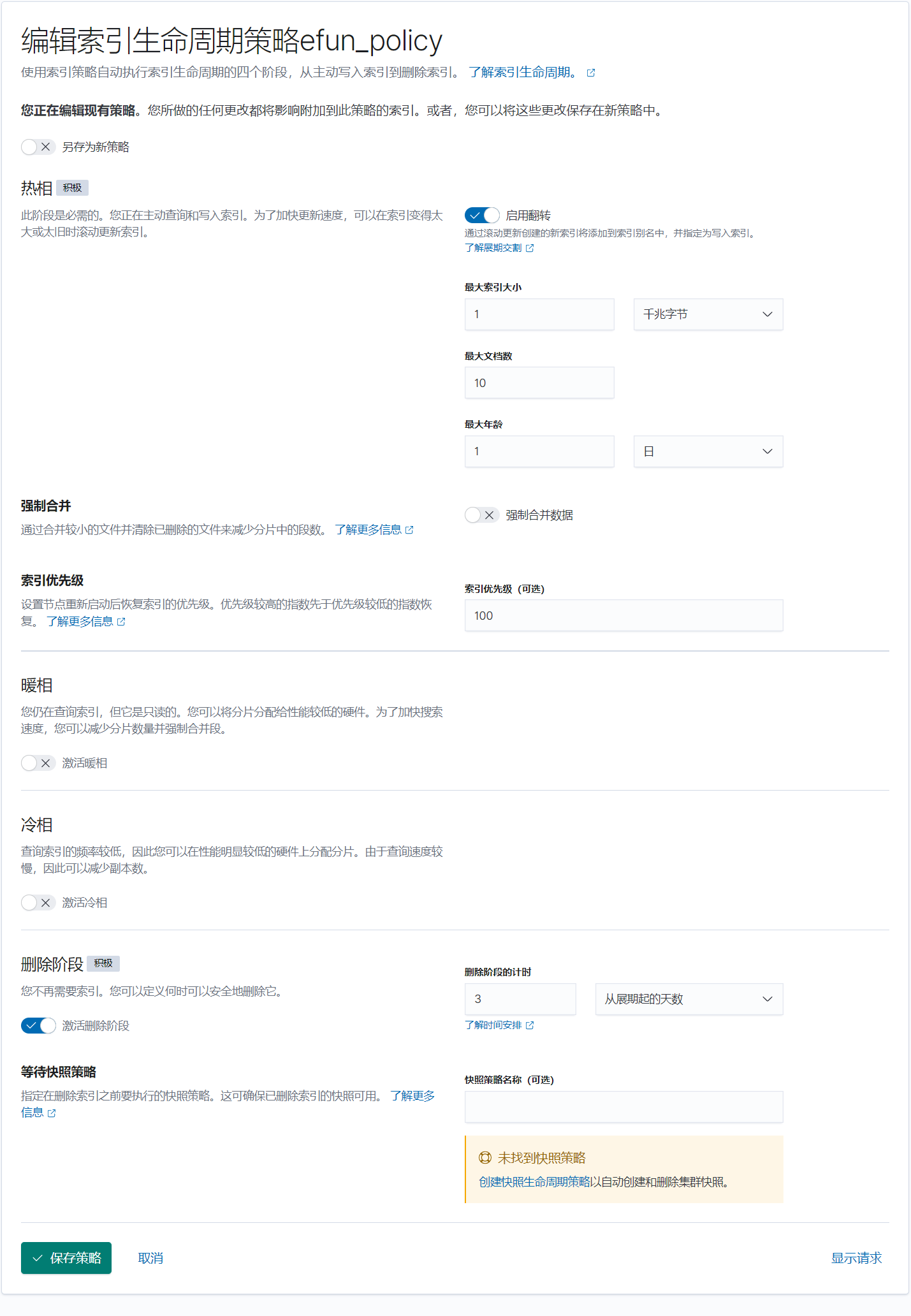
ILM定期运行(indices.lifecycle.poll_interval),默认是10分钟,检查索引是否符合策略标准,并执行所需的任何步骤。
为了避免争用情况,ILM可能需要运行多次以执行完成一项动作所需的所有步骤。所以,即使indices.lifecycle.poll_interval设置为10分钟并且索引符合rollover,也可能需要20分钟才能完成rollover。
我们为了方便测试进行一下设置改为5s
1 | PUT _cluster/settings |
设置索引模板
1 | PUT _index_template/efuntest01 |
可以使用可视化页面直接进行管理
配置格式
1 | output { |
这里有几个注意的地方
user和password需要用引号包裹住, 否则可能会报错- 如果指定了
ilm_rollover_alias就可以不写index - logstash在启动的时候会先去创建一个索引模板来进行匹配
ilm_pattern里面不能有%所以时间要用{now/d}
跑起来
./bin/logstash -f ./config/file_grok_es_01.conf
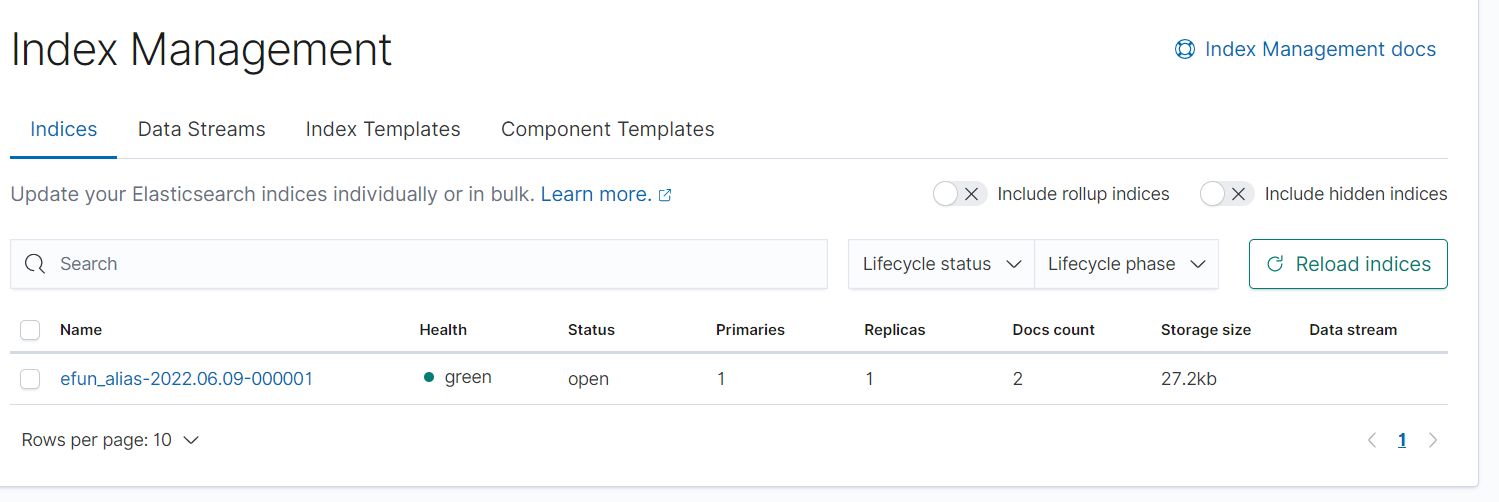
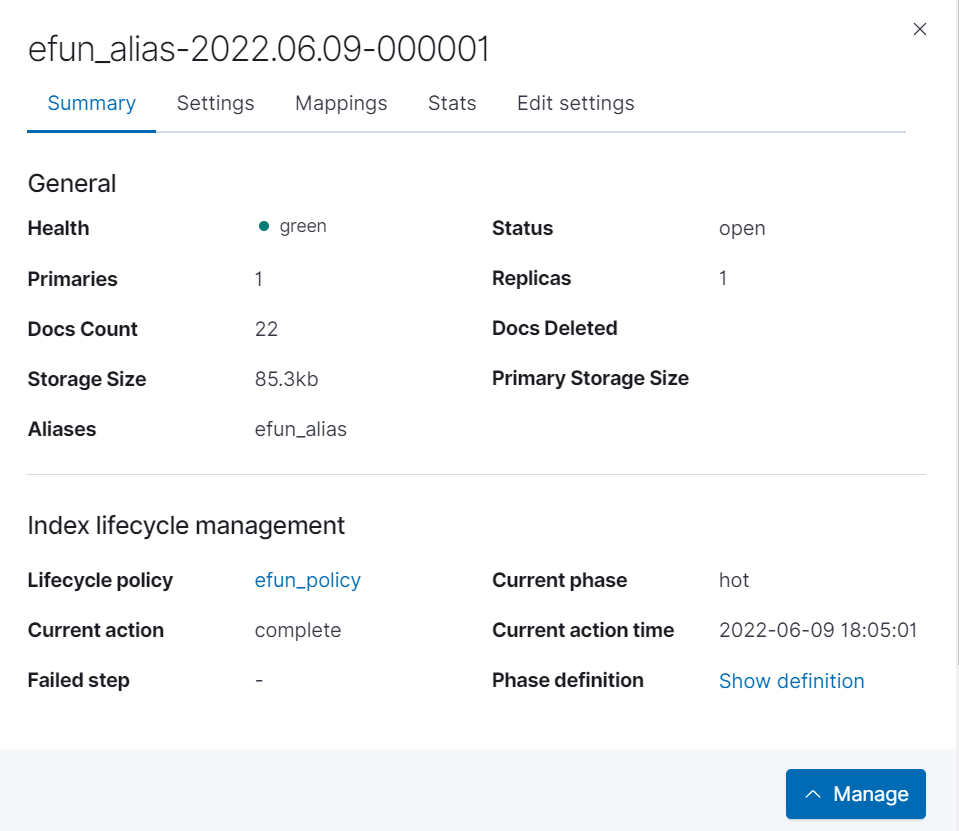
已经出现数据, 我们继续刷数据让他达到10条进行翻滚
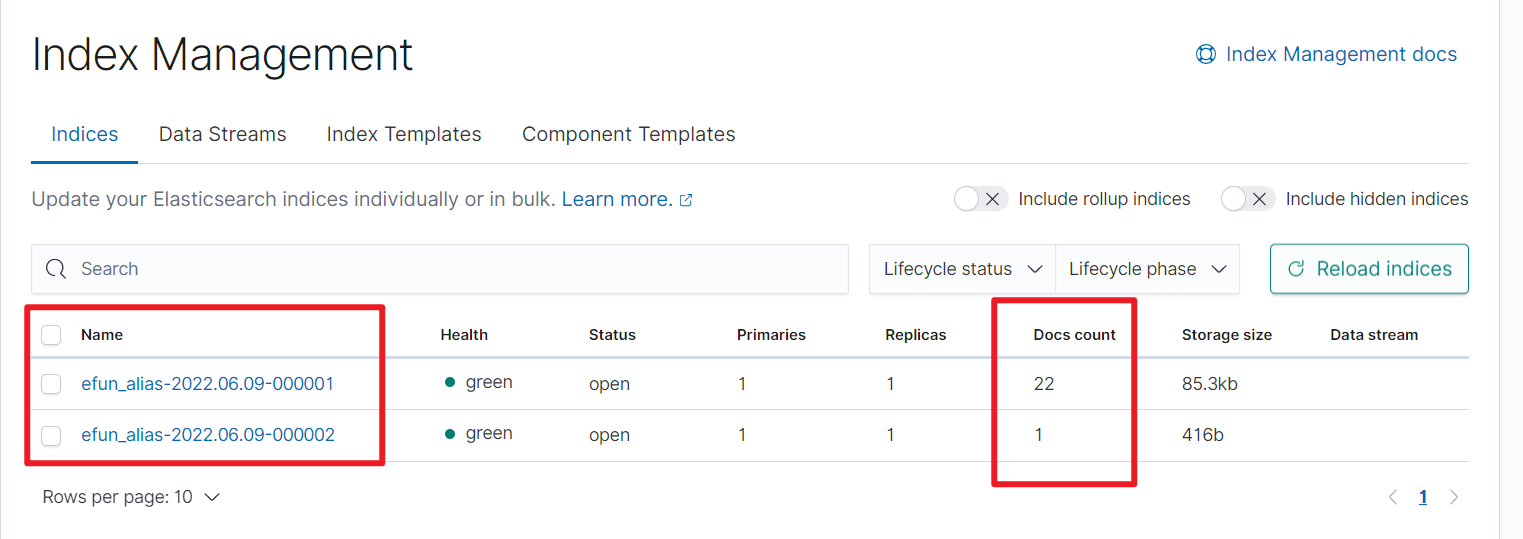
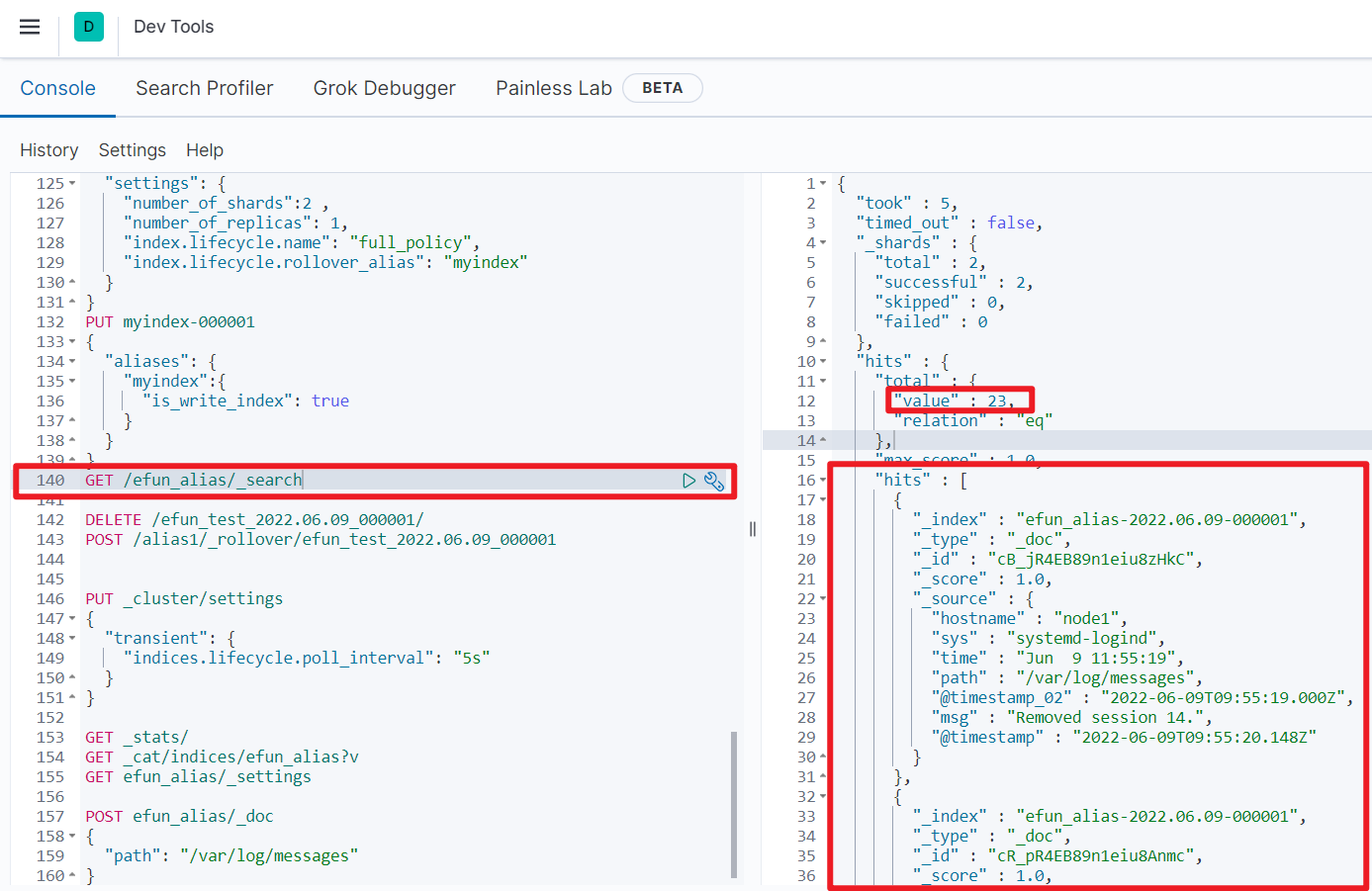
这里刷新频率是5s, 发现达到条件之后进行翻滚, 并不是每次只翻滚10条






