Pandas学习笔记
官方文档:官方英文文档
Series和DataFrame简介
Series是==一维==
Dataframe是==二维==,如:excel表 mysql表
是pandas中最基础的数据结构
Series基本用法
Series 由索引(index)和列组成,函数如下:
1 2 3 4 5 6 7 8 pandas.Series( data, index, dtype, name, copy) 参数说明: #data:一组数据(ndarray 类型)。 #index:数据索引标签,如果不指定,默认从 0 开始。 #dtype:数据类型,默认会自己判断。 #name:设置名称。 #copy:拷贝数据,默认为 False。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 a = [1,2,3] sr = pd.Series(a) sr 0 1 1 2 2 3 dtype: int64 ### b = pd.Series(['abc', 'def'], index=['name', 'sex']) b name abc sex def dtype: object ### d=pd.Series(a,['x','y','z'],name='i am a name') d x 1 y 2 z 3 # jupyter notebook中可以省略print语句,直接在单元格中运行某个变量就可以得到输出结果
Series常用属性 名称 属性 axes 以列表的形式返回所有行索引标签。 dtype 返回对象的数据类型。 empty 返回一个空的 Series 对象。 ndim 返回输入数据的维数。 size 返回输入数据的元素数量。 values 以 ndarray 的形式返回 Series 对象。 index 返回一个RangeIndex对象,用来描述索引的取值范围。
Series常用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 增删改查: # 增 (第一,直接下标索引或index添加;第二,通过append()添加,生成新的Series) data[3] = 100 # 用index增添 data['a'] = 200 data.append(3) # 用append()增添 # 删(第一,用del删除;第二,用.drop()删除,会生成新的Series) del data['a'] # 用del删除 data.drop(['c', 'd']) # 用.drop()删除,删除多个要加[] # 改(通过索引直接修改) data[1] = 100 data[['c', 'd']] = 200 # 查 data[2] data.head(n) # 默认查看前5行 data.tail(n) # 默认查看后5行 #其他常用方法: max() # 最大 min() # 最小 mean() # 平均 std() # 标准差,反应的是一组数据中和平均值的差异程度 count() # 返回非空值的数量 pd.isnull(data) #返回都是布尔值的series pd.notnull(data) data.info() # 基本信息 data.isnull() # 返回每个是否为空 data.describe() # 综合统计
DataFrame基本用法
1 2 3 4 5 6 7 8 pandas.DataFrame( data, index, columns, dtype, copy) #参数说明: #data:一组数据(ndarray、series, map, lists, dict 等类型)。 #index:索引值,或者可以称为行标签。 #columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。 #dtype:数据类型。 #copy:拷贝数据,默认为 False。
1 2 3 4 5 6 7 8 9 10 pd.DataFrame(data={'Name':['Tome','Bob'], 'Occupation':['Teacher','IT Engineer'], 'age':[28,36]}) # 创建时没有指定行索引,会自动创建0, 1作为行索引,字典中的key,自动作为列名 a = pd.DataFrame(data={'Occupation':['Teacher','IT Engineer'], 'age':[28,36]}, index=['Tom', 'bob']) # 创建时指定索引(index),不会自动床架你0 1作为索引,按照指定的值去创建索引 a.index 行索引 Index类型 a.columns 列名 Index类型
DataFrame属性 参数 说明 dat 支持多种数据类型,如:ndarray,series,map,lists,dict,constant和另一个DataFrame。 index 行索引,如果没有传递索引值,默认值为np.arrange(n) columns 列索引,如果没有传递索引值,默认值为np.arrange(n) dtyp 每列的数据类型。 copy 是否复制数据,默认值为False shape 形状(4916, 28) 4916行,28列,是一个二维数据 size 总个数
DataFrame常用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 df.count() # 对每个列进行count() 得到的是非空元素的数量 df.min() df.max() df.mean() df.empty() # 返回一个布尔值,判断输出的数据对象是否为空,若为 True 表示对象为空。 df.dtypes()# 返回每一列的数据类型 df.describe() # 默认统计数值列指标 df.describe(include=object) # 统计的字符串类型的列的指标 df.describe(include='all') # 统计所有列的统计指标 df.loc()#通过行索引标签获取指定行数据,用的索引名取数据,根据索引的实际情况可能是数字,也可能是字符串 df.iloc()#用的行号取数据,只能是整数 df.[] #如果只用方括号取值,取出的series类型,两个方括号就是dataframe df.head(1) df.tail(1)# 都是dataframe类型 df.loc[[行索引名],[列名]]#取出所有行,可以使用切片语法 df.loc[ : , [列名]] df.iloc[[行号], [列号]]#df.iloc[:,[列序号]] # 列序号可以使用-1代表最后一列 df.iloc[[0,99,999],[0,3,5]] df.loc[[0,99,999],['country','lifeExp','gdpPercap']] #获取多行多列,可读性更强
Pandas 描述性统计
函数名称
描述说明
count()
统计某个非空值的数量。
sum()
求和
mean()
求均值
median()
求中位数
mode()
求众数
std()
求标准差
min()
求最小值
max()
求最大值
abs()
求绝对值
prod()
求所有数值的乘积。
cumsum()
计算累计和,axis=0,按照行累加;axis=1,按照列累加。
cumprod()
计算累计积,axis=0,按照行累积;axis=1,按照列累积。
corr()
计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。
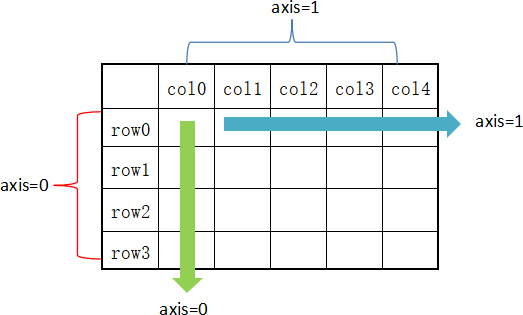
在 DataFrame 中,使用聚合类方法时需要指定轴(axis)参数。下面介绍两种传参方式:
对行 操作,默认使用 axis=0 或者使用 “index”;
对列 操作,默认使用 axis=1 或者使用 “columns”。
数据汇总描述 **describe()**函数
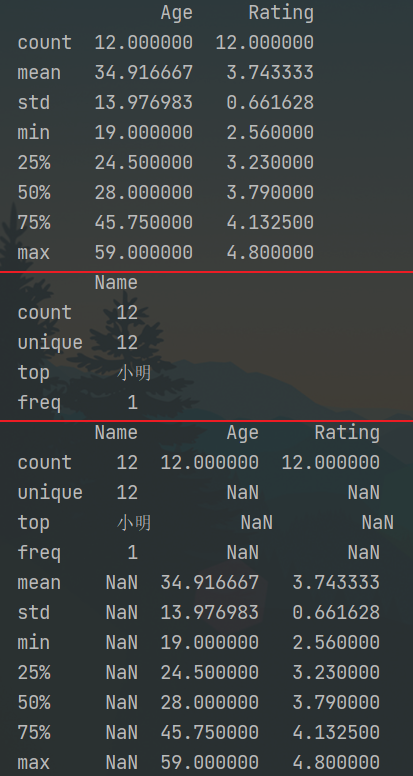
1 2 3 4 5 6 7 8 9 10 import pandas as pd d = {'Name': pd.Series(['小明', '小亮', '小红', '小华', '老赵', '小曹', '小陈', '老李', '老王', '小冯', '小何', '老张']), 'Age': pd.Series([25, 26, 25, 23, 59, 19, 23, 44, 40, 30, 51, 54]), 'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8, 3.78, 2.98, 4.80, 4.10, 3.65]) } df = pd.DataFrame(d) print(df.describe()) # 默认只计算数值 print(df.describe(include=["object"])) # 统计字符串 print(df.describe(include="all")) # 统计所有
运行结果:
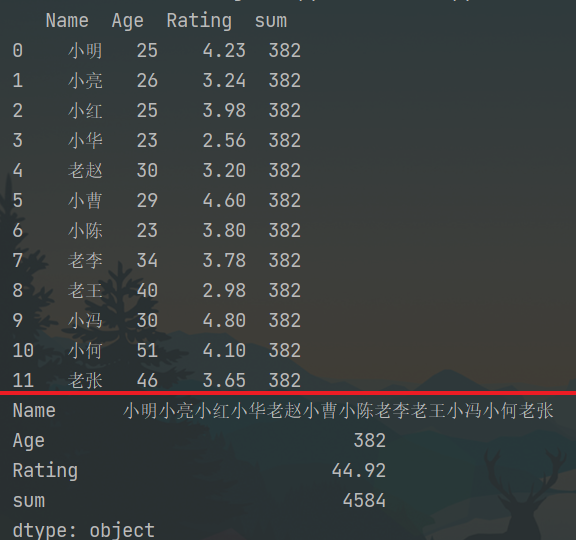
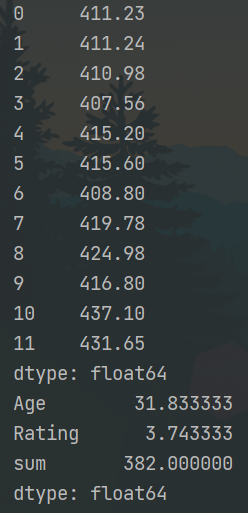
和均积 计算 1 2 3 4 5 6 7 8 9 10 11 12 import pandas as pd d = {'Name': pd.Series(['小明', '小亮', '小红', '小华', '老赵', '小曹', '小陈', '老李', '老王', '小冯', '小何', '老张']), 'Age': pd.Series([25, 26, 25, 23, 30, 29, 23, 34, 40, 30, 51, 46]), 'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8, 3.78, 2.98, 4.80, 4.10, 3.65]) } df = pd.DataFrame(d) df['sum'] = df.Age.sum() print(df) print(df.sum()) # 默认为列 print(df.sum(1)) # 也可使用sum("columns") print(df.mean())
运行结果:
Pandas 数据导入导出 Pandas支持众多数据的读写:Pickling,Flat file,Clipboard,Excel,JSON,HTML,XML,Latex,HDFStore: PyTables (HDF5),Feather,Parquet,ORC,SAS,SPSS,SQL,Google BigQuery,STATA…
我们在此先学习三种文件格式,其他可参考官网。
Pickle文件 二进制文件,直接把内存中的数据保存到文件中,不用转换格式,自动识别,后续加载直接把数据恢复到内存即可
1 2 3 pd.read_pickle('xxx.pkl') # 读 series.to_pickle('xxx.pkl') # 写 df.to_pickle('xxx.pkl') # 写
CSV文件 本质上就是一个文本文件,每一行都是由逗号分隔出若干个字段
1 2 3 4 5 6 pd.read_csv('xxx.csv', sep=',', index_col='') df.to_csv('xxx.csv', sep=',', index=True) # sep指定分隔符,默认是逗号,可以指定任意一个字符作为分隔符,指定成\t可以得到一个tsv文件。如果保存时指定分隔符,在加载时必须指定相同分隔符,才能加载 # index,默认会把df中行索引保存到文件中,可以设置成False # sep设置和to_csv时是一致的 # 如果保存时index设置的是True,可以在加载时指定'Unnamed: 0'作为索引 也可以直接把'Unnamed: 0'删除
Excel文件 微软Excel文件,需要安装相关依赖
1 2 3 4 5 #记得装Excel依赖:xlwt openpyxl xlrd pd.read_excel('xxx.xlsx', sheet_name='表名') #读 df.to_excel('xxx.xlsx', sheet_name='表名', index=False) #写 # sheet_name 指定的是excel表左下角的名字 默认'Sheet1' # index 是否保存索引 默认为 True
to_excel() 参数名称
描述说明
excel_wirter
文件路径或者 ExcelWrite 对象。
sheet_name
指定要写入数据的工作表名称。
na_rep
缺失值的表示形式。
float_format
它是一个可选参数,用于格式化浮点数字符串。
columns
指要写入的列。
header
写出每一列的名称,如果给出的是字符串列表,则表示列的别名。
index
表示要写入的索引。
index_label
引用索引列的列标签。如果未指定,并且 hearder 和 index 均为为 True,则使用索引名称。如果 DataFrame 使用 MultiIndex,则需要给出一个序列。
startrow
初始写入的行位置,默认值0。表示引用左上角的行单元格来储存 DataFrame。
startcol
初始写入的列位置,默认值0。表示引用左上角的列单元格来储存 DataFrame。
engine
它是一个可选参数,用于指定要使用的引擎,可以是 openpyxl 或 xlsxwriter。
read_excel() 参数名称
说明
io
表示 Excel 文件的存储路径。
sheet_name
要读取的工作表名称。
header
指定作为列名的行,默认0,即取第一行的值为列名;若数据不包含列名,则设定 header = None。若将其设置 为 header=2,则表示将前两行作为多重索引。
names
一般适用于Excel缺少列名,或者需要重新定义列名的情况;names的长度必须等于Excel表格列的长度,否则会报错。
index_col
用做行索引的列,可以是工作表的列名称,如 index_col = ‘列名’,也可以是整数或者列表。
usecols
int或list类型,默认为None,表示需要读取所有列。
squeeze
boolean,默认为False,如果解析的数据只包含一列,则返回一个Series。
converters
规定每一列的数据类型。
skiprows
接受一个列表,表示跳过指定行数的数据,从头部第一行开始。
nrows
需要读取的行数。
skipfooter
接受一个列表,省略指定行数的数据,从尾部最后一行开始。
Pandas reindex重置索引 set_index( )和reset_index( )以及reindex()区别:
set_index():将某列设置为索引
重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
reindex()方法的格式:DataFrame.reindex(labels=None,index=None,axis=None,method=None,copy=True,level=None,fill_values=nan,limit=None,tolerance=None)
serise.reindex()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import numpy as np import pandas as pd from pandas import Series, DataFrame np.random.seed(666) # series reindex s1 = Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D']) print(s1) ''' A 1 B 2 C 3 D 4 dtype: int64 ''' # 重新指定 index, 多出来的index,可以使用fill_value 填充 print(s1.reindex(index=['A', 'B', 'C', 'D', 'E'], fill_value = 10)) ''' A 1 B 2 C 3 D 4 E 10 dtype: int64 ''' s2 = Series(['A', 'B', 'C'], index = [1, 5, 10]) print(s2) ''' 1 A 5 B 10 C dtype: object ''' # 修改索引, # 将s2的索引增加到15个 # 如果新增加的索引值不存在,默认为 Nan print(s2.reindex(index=range(15))) ''' 0 NaN 1 A 2 NaN 3 NaN 4 NaN 5 B 6 NaN 7 NaN 8 NaN 9 NaN 10 C 11 NaN 12 NaN 13 NaN 14 NaN dtype: object ''' # ffill : foreaward fill 向前填充, # 如果新增加索引的值不存在,那么按照前一个非nan的值填充进去 print(s2.reindex(index=range(15), method='ffill')) ''' 0 NaN 1 A 2 A 3 A 4 A 5 B 6 B 7 B 8 B 9 B 10 C 11 C 12 C 13 C 14 C dtype: object '''
dataframe.reindex()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 # reindex dataframe df1 = DataFrame(np.random.rand(25).reshape([5, 5]), index=['A', 'B', 'D', 'E', 'F'], columns=['c1', 'c2', 'c3', 'c4', 'c5']) print(df1) ''' c1 c2 c3 c4 c5 A 0.700437 0.844187 0.676514 0.727858 0.951458 B 0.012703 0.413588 0.048813 0.099929 0.508066 D 0.200248 0.744154 0.192892 0.700845 0.293228 E 0.774479 0.005109 0.112858 0.110954 0.247668 F 0.023236 0.727321 0.340035 0.197503 0.909180 ''' # 为 dataframe 添加一个新的索引 # 可以看到 自动 扩充为 nan print(df1.reindex(index=['A', 'B', 'C', 'D', 'E', 'F'])) ''' 自动填充为 nan c1 c2 c3 c4 c5 A 0.700437 0.844187 0.676514 0.727858 0.951458 B 0.012703 0.413588 0.048813 0.099929 0.508066 C NaN NaN NaN NaN NaN D 0.200248 0.744154 0.192892 0.700845 0.293228 E 0.774479 0.005109 0.112858 0.110954 0.247668 F 0.023236 0.727321 0.340035 0.197503 0.909180 ''' # 扩充列, 也是一样的 print(df1.reindex(columns=['c1', 'c2', 'c3', 'c4', 'c5', 'c6'])) ''' c1 c2 c3 c4 c5 c6 A 0.700437 0.844187 0.676514 0.727858 0.951458 NaN B 0.012703 0.413588 0.048813 0.099929 0.508066 NaN D 0.200248 0.744154 0.192892 0.700845 0.293228 NaN E 0.774479 0.005109 0.112858 0.110954 0.247668 NaN F 0.023236 0.727321 0.340035 0.197503 0.909180 NaN ''' # 减小 index print(s1.reindex(['A', 'B'])) ''' 相当于一个切割效果 A 1 B 2 dtype: int64 ''' print(df1.reindex(index=['A', 'B'])) ''' 同样是一个切片的效果 c1 c2 c3 c4 c5 A 0.601977 0.619927 0.251234 0.305101 0.491200 B 0.244261 0.734863 0.569936 0.889996 0.017936 ''' # 对于一个 serie 来说,可以使用 drop,来丢掉某些 index print(s1.drop('A')) ''' 就只剩下 三个了 B 2 C 3 D 4 dtype: int64 ''' # dataframe drop(A) 直接去掉一行 print(df1.drop('A', axis=0)) ''' axis 默认 是 行 c1 c2 c3 c4 c5 B 0.571883 0.254364 0.530883 0.295224 0.352663 D 0.858452 0.379495 0.593284 0.786078 0.949718 E 0.556276 0.643187 0.808664 0.289422 0.501041 F 0.737993 0.286072 0.332714 0.873371 0.421615 ''' print(df1.drop('c1', axis=1)) ''' 将 c1 的列 去掉 c2 c3 c4 c5 A 0.326681 0.247832 0.601982 0.145905 B 0.373961 0.393819 0.439284 0.926706 D 0.558490 0.617851 0.461280 0.373102 E 0.030434 0.566498 0.383103 0.739243 F 0.982220 0.989826 0.957863 0.411514 '''
Pandas 简单分组排序 分组 在 Pandas 中,要完成数据的分组操作,需要使用 groupby() 函数,它和 SQL 的GROUP BY操作非常相似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import pandas as pd import numpy as np df1 = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'], 'key2':['one', 'two', 'one', 'two', 'one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)}) #按key1进行分组,并计算data1列的平均值 a = df1.groupby('key1').mean() # 按key1,key2进行分组,并计算data1,2列的平均值 b = df1.groupby(['key1','key2']).mean() # 以key1分组,只去data1 c = df1.groupby(['key1'])['data1'].mean() # 分组后的数据可以是个可迭代对象 d =df1.groupby(['key1']) d=list(d) print(type(d)) for i in d: print(i)
排序 sort_values() 1 2 3 4 5 6 7 8 9 10 11 12 作用:既可以根据列数据,也可根据行数据排序。 注意:必须指定by参数,即必须指定哪几行或哪几列;无法根据index名和columns名排序(由.sort_index()执行) 调用方式 DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last') axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。 by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名"。 ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。 inplace:布尔型,是否用排序后的数据框替换现有的数据框。 kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。 na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
1 2 3 df.sort_values('b') #按b列升序排列 df.sort_values(by=['b','a'],axis=0,ascending=[False,True]) #先按b列降序,再按a列升序排序 df.sort_values(by=3,axis=1) # 按行3升序排列
指定多列(多行)排序时 ,先按排在前面的列(行)排序,如果内部有相同数据,再对相同数据内部用下一个列(行)排序,以此类推。如何内部无重复数据,则后续排列不执行。即首先满足排在前面的参数的排序,再排后面参数
sort_index() 1 2 3 4 5 6 7 8 9 10 11 12 13 作用:默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。 注意:df. sort_index()可以完成和df. sort_values()完全相同的功能,但python更推荐用只用df. sort_index()对“根据行标签”和“根据列标签”排序,其他排序方式用df.sort_values()。 **调用方式** sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None) axis:0按照行名排序;1按照列名排序 level:默认None,否则按照给定的level顺序排列---貌似并不是 ascending:默认True升序排列;False降序排列 inplace:默认False,否则排序之后的数据直接替换原来的数据框 kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。 na_position:缺失值默认排在最后{"first","last"} by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
1 2 df.sort_index() #默认按“行标签”升序排序,或df.sort_index(axis=0, ascending=True) df.sort_index(axis=1) #按“列标签”升序排序
Pandas 查看函数loc/iloc用法 1 2 3 4 5 6 7 8 9 10 df['Low'] # 查看单列 df[['Low','Shares']] # 查看多列 df.loc[1] #查 看某行(按索引标签) df.loc[[1,2]] # 查看多行 df.loc[0:2] # 切片,注意此处:闭区间,包含两端 df.iloc[0] # 纯粹按数字索引 从0开始 df.iloc[0,1] df.iloc[0:2]
Pandas 去重处理 数据去重可以使用duplicated()和drop_duplicates()两个方法。
1 2 3 4 5 6 DataFrame.duplicated(subset = None,keep =‘first' )返回boolean Series表示重复行 参数: subset:列标签或标签序列,可选 仅考虑用于标识重复项的某些列,默认情况下使用所有列 keep:{‘first',‘last',False},默认'first'
1 2 3 4 5 6 7 8 9 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)[source] 参数: keep{‘first’, ‘last’, False}, default ‘first’ inplacebool, default False 删除重复或返回副本。 ignore_indexbool, default False If True, the resulting axis will be labeled 0, 1, …, n - 1.(重置索引)
1 2 3 4 df['Xylene'].duplicated() # 查看重复值 df.drop_duplicates('Xylene') df['Xylene'].drop_duplicates() df.drop_duplicates('Xylene',keep='last') # 参数 keep 可以标记保留重复值{'first','last',False}默认第一个
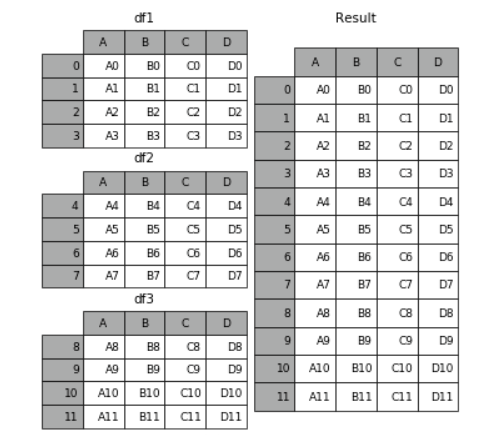
Pandas 数据集合并 concat() 1 2 3 4 5 6 7 8 9 10 11 12 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None,verify_integrity=False,copy=True) objs:**Series,DataFrame或Panel对象的序列或映射**。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。 axis:{0,1,...},默认为0。沿着连接的轴。 join:{'inner','outer'},默认为“outer”。如何处理其他轴上的索引。outer为联合和inner为交集。 ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,...,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。 join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。 keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。 levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。 names:list,default无。结果层次索引中的级别的名称。 verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。 copy:boolean,default True。如果为False,请勿不必要地复制数据。
1 row_concat = pd.concat([df1,df2,df3])
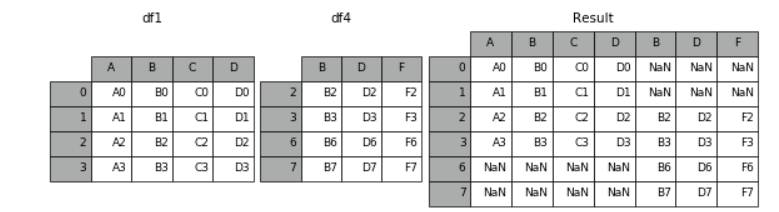
1 result = pd.concat([df1, df4], axis=1) # 默认join = 'outer',为取并集的关系
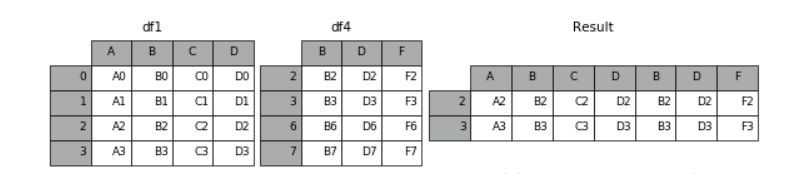
1 result = pd.concat([df1, df4], axis=1, join='inner') # 当设置join = 'inner',则说明为取交集
merge() merge即是类函数也是实例函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)[source] 参数: left 左边的DataFrame right 右边的DataFrame how 'inner’,'outer','left','right'之一,默认是'inner' on 需要连接的列名,必须是在两边的DataFrame对象都有的列名,并以left和right中的列名的交集作为连接键 left_on left DataFrame中用做连接的键 right_on right DataFrame中用做连接的键 left_index 使用left的行索引作为他的连接键(如果是multiindex,则是多个键) right_index 使用right的行索引作为他的连接键(如果是multiindex,则是多个键) sort 通过连接键按字母顺序对合并的数据进行排序,默认为True suffixes 在重叠情况下,添加到列名都得字符串元组,默认是(‘_x’,'_y') copy 默认True indicator 添加一个特殊的列,指示每一行的来源:值将根据每行中连接数据的来源分别left_only,right_onlt,both
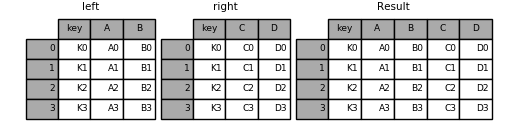
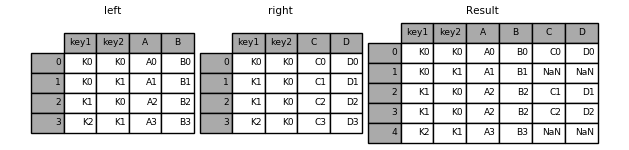
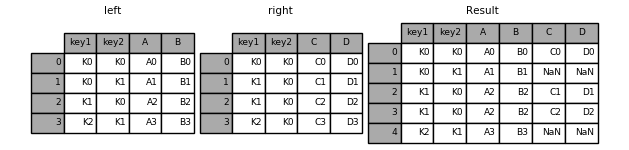
1 pd.merge(left, right, on='key')
1 pd.merge(left, right, on=['key1', 'key2'])
Merge 方法
类比的SQL连接名称
描述
left
LEFT OUTER JOIN
使用左侧框架中的键
right
RIGHT OUTER JOIN
使用右侧框架中的建
outer
FULL OUTER JOIN
使用来自两个集的键的联合
inner
INNER JOIN
使用两个集的建的交集
1 In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
1 In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])
1 In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
1 In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])
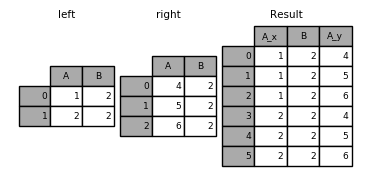
另一个在 DataFrames 中具有重复连接键的示例:
1 2 3 4 5 In [49]: left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]}) In [50]: right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]}) In [51]: result = pd.merge(left, right, on='B', how='outer')
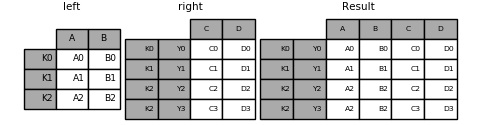
join() 1 2 3 4 5 6 7 8 9 join(other, on=None, how=“left”, lsuffix="", rsuffix="", sort=False) 参数: other:DataFrame, Series, or list of DataFrame,另外一个dataframe, series,或者dataframe list。 on: 参与join的列,与sql中的on参数类似。 how: {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’, 与sql中的join方式类似。 lsuffix: 左DataFrame中重复列的后缀 rsuffix: 右DataFrame中重复列的后缀 sort: 按字典序对结果在连接键上排序
1 In [98]: result = left.join(right, how='inner')
Pandas 缺失值处理 Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan
缺失值和其它类型的数据不同,它不等于0,也不等于空串和False,
检查缺失值 Pandas 提供了 isnull()/isna() 和 notnull()/notna() 函数,它们同时适用于 Series 和 DataFrame 对象
1 2 df['noe'].isnull/isna() # 返回布尔类型 df['one'].notnull/notna() # 返回布尔类型
缺失数据计算 首先数据求和时,将 NA 值视为 0 ,其次,如果要计算的数据为 NA,那么结果就是 NA。
1 2 3 4 # 加载数据时可以通过keep_default_na 与 na_values 指定加载数据时的缺失值 # keep_default_na如果True,na_values就不生效 print(pd.read_csv('data/survey_visited.csv',keep_default_na = False)) print(pd.read_csv('data/survey_visited.csv',na_values=[""],keep_default_na = False))
删除缺失值
如果想删除缺失值,那么使用 dropna() 函数与参数 axis 可以实现。在默认情况下,按照 axis=0 来按行处理,这意味着如果某一行中存在 NaN 值将会删除整行数据。
DataFrme.dropna(axis=0,how=’any’,thresh=None,subset=None,inplace=False)
1 2 3 4 df.dropna() #某行中有缺失值则删全行 df.dropna(axis=1) #某行中有缺失值则删全列 df.dropna(axis=0,how='all',subset=['Embarked']) #Embarked该列中有缺失值则删除该行 df.dropna(axis=1) #某行中有缺失值则删全列
填充缺失值 fillna() 函数可以实现用非空数据“填充”NaN 值
1 2 3 df.fillna(0) # 用0替换NaN值 df.fillna(method="ffill") # 向前填充缺失值 df.fillna(method="bfill") # 向后填充缺失值
使用replace()替换通用值
1 df.replace({1:10,6:60,2:20}) # 1替换成10,6替换成60.....
1 2 3 msno.bar(train) # 缺失值 msno.matrix(train) # 缺失值的位置 msno.heatmap(train) #热力图 相关性
Pandas 整理数据 melt() pandas的melt函数可以把宽数据集,转换为长数据集
melt即是类函数也是实例函数,也就是说既可以用pd.melt, 也可使用dataframe.melt()
参数
类型
说明
frame
dataframe
被 melt 的数据集名称在 pd.melt() 中使用
id_vars
tuple/list/ndarray
可选项不需要被转换的列名 ,在转换后作为标识符列(不是索引列)
value_vars
tuple/list/ndarray
可选项需要被转换的现有列 如果未指明,除 id_vars 之外的其他列都被转换
var_name
string
variable 默认值自定义列名名称设置由 ‘value_vars’ 组成的新的 column name
value_name
string
value 默认值自定义列名名称设置由 ‘value_vars’ 的数据组成的新的 column name
col_level
int/string
可选项如果列是MultiIndex,则使用此级别
1 2 # 把宽数据集,转换为长数据集 pew_long =pew.melt(id_vars='religion',var_name='income',value_name='count')# religion不转换,并重命名列
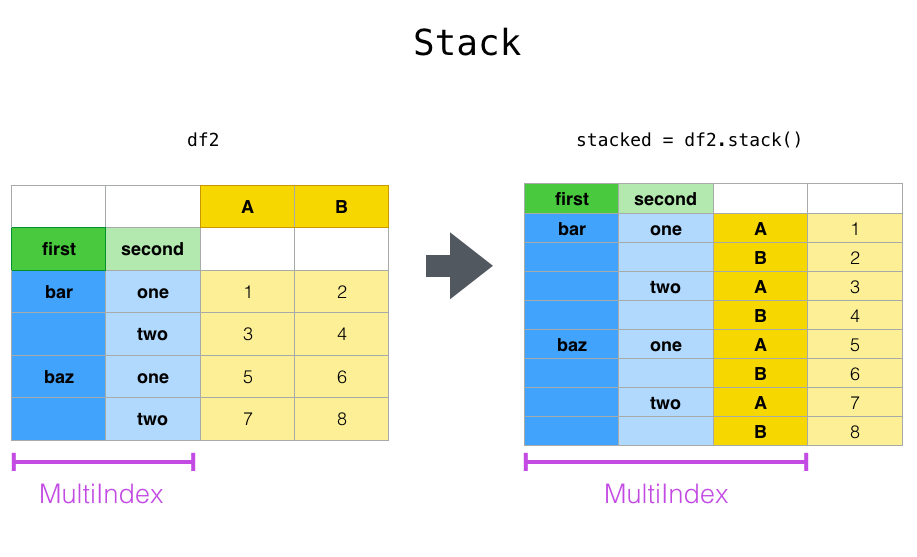
stack() 堆叠 堆叠
stack也是宽数据转长数据
stack:“透视”某个级别的(可能是多层的)列标签,返回带有索引的 DataFrame,该索引带有一个新的最里面的行标签。
1 df_single_level_cols.stack()
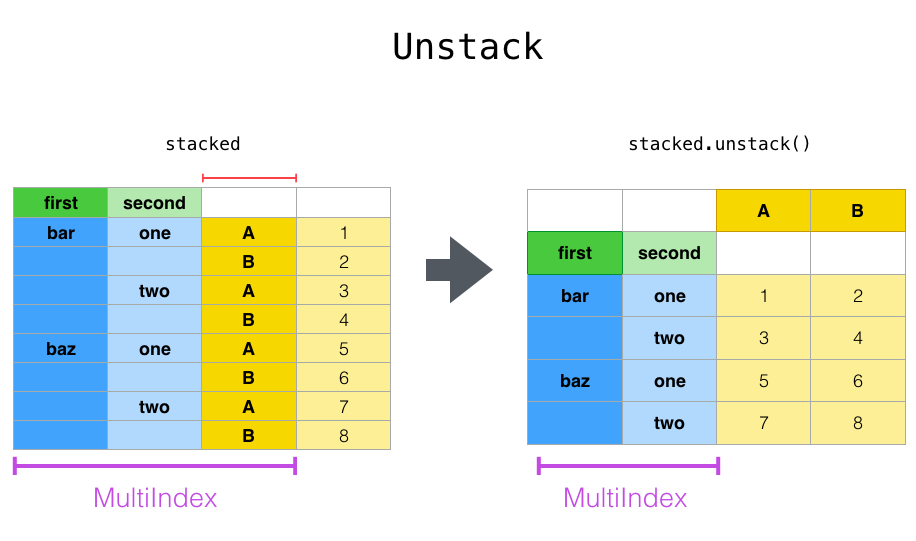
unstack() 反堆叠 取消堆叠
unstack:(堆栈的逆操作)将(可能是多层的)行索引的某个级别“透视”到列轴,从而生成具有新的最里面的列标签级别的重构的 DataFrame。
wide_to_long()
pandas 的 pd.wide_to_long() 可完成长表转宽表的操作。与数据融合方法 pandas.melt() 相似,pd.wide_to_long() 可以通过列名的规则解析成行数据,比 pandas.melt() 更加灵活好用。pandas 提供了长转宽和宽转长表各种方法,宽型转长型数据有 melt(数据融合) 和 wide_to_long 两种方法,长型数据转为宽型数据可以通过透视的功能实现,有 pivot 及 pivot_table 等。
1 2 3 4 5 6 7 8 9 10 11 12 wide_to_long(df, stubnames, i, j, sep='', suffix='\\d+') 逻辑说明: 使用 stubnames ['A', 'B'],这个函数期望找到一个或多个带格式的列组 A-suffix1, A-suffix2,..., B-suffix1, B-suffix2,... 在生成的长格式中指定要调用此后缀的内容使用 j(例如j='year')假设这些宽变量的每一行都由 i(可以是单个列名或列名列表)数据框中所有剩余的变量都保持不变。 参数: df : DataFrame 数据,是一个 wide-format 数据 stubnames : str or list-like,存根(或者占坑、桩,stub)名称。宽格式变量假定以存根名称开头 i : str or list-like,用作 id 变量的列 j : str,子观察变量的名称,希望以长格式命名后缀 sep : str, default "",一个表示变量名分隔的字符在宽格式中,从长格式中的名称中删除。例如,如果您的列名是 A-suffix1、A-suffix2,则您可以通过指定 sep='-' 去除连字符 suffix : str, default '\d+',捕获所需后缀的正则表达式。 '\d+' 捕获数字后缀,可以指定没有数字的后缀否定字符类 '\D+'。 您还可以进一步消除歧义后缀,例如,如果您的宽变量是 A-one 形式,B-2,..,并且您有一个不相关的列 A-评级,您可以忽略最后一个通过指定suffix='(!?onetwo)'。 当所有后缀都是数字,它们被转换为 int64/float64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 np.random.seed(123) df = pd.DataFrame({"A1970" : {0 : "a", 1 : "b", 2 : "c"}, "A1980" : {0 : "d", 1 : "e", 2 : "f"}, "B1970" : {0 : 2.5, 1 : 1.2, 2 : .7}, "B1980" : {0 : 3.2, 1 : 1.3, 2 : .1}, "X" : dict(zip(range(3), np.random.randn(3))) }) df["id"] = df.index pd.wide_to_long(df, ["A", "B"], i="id", j="year") df = pd.DataFrame({ 'famid': [1, 1, 1, 2, 2, 2, 3, 3, 3], 'birth': [1, 2, 3, 1, 2, 3, 1, 2, 3], 'ht1': [2.8, 2.9, 2.2, 2, 1.8, 1.9, 2.2, 2.3, 2.1], 'ht2': [3.4, 3.8, 2.9, 3.2, 2.8, 2.4, 3.3, 3.4, 2.9] }) l = pd.wide_to_long(df, stubnames='ht', i=['famid', 'birth'], j='age')
Pandas 数据类型 Pandas 自定义函数 类比Python中map函数
1 2 3 4 def f(x): return x*2 l=map(f, [1, 23, 4]) list(l)
apply()
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)
该函数最有用的是第一个参数 ,这个参数是函数,相当于C/C++的函数指针。 这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def f(x): return x*2 def f2(x,a): return x*a def f3(a): return sum(a)/len(a) # 每次是取一列 @np.vectorize def vec_avg_2_mod(x,y): if(x==20): return (np.NaN) else: return (x+y)/2 data.apply(f) data.apply(f2,a=4) data.apply(f3,axis=1) vec_avg_2_mod(df['a'],df['b']) data.apply(lambda x: x+1)
Pandas 数据分组 Pandas方法
Numpy函数
说明
count
np.count_nonzero
频率统计(不包含NaN值)
size
频率统计(包含NaN值)
mean
np.mean
求平均值
std
np.std
标准差
min
np.min
最小值
quantile()
np.percentile()
分位数
max
np.max
求最大值
sum
np.sum
求和
var
np.var
方差
describe
计数、平均值、标准差,最小值、分位数、最大值
first
返回第一行
last
返回最后一行
nth
返回第N行(Python从0开始计数
单变量分组聚合 1 2 3 df.loc[df.year==1952,:] df[df.year==1952]['lifeExp'].mean() df.groupby('year').lifeExp.mean()
聚合函数
agg()
DataFrame.agg(func, axis=0, *args, **kwargs)
func : function, str, list 或 dict 函数,用于聚合数据。如果是函数, 则必须在传递DataFrame或传递到DataFrame.apply时工作。 axis : {0 or ‘index’, 1 或 ‘columns’}, 默认 0
agg是一个聚合函数,聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,不同于 numpy聚合函数
1 df.groupby('continent').lifeExp.describe()
其他库的函数
1 df.groupby('continent').lifeExp.agg(np.mean)
自定义函数 自定义函数中只有一个参数values, 但传入该函数中的数据是一组值, 需要对values进行迭代才能取出每一个值 自定义函数可以有多个参数, 第一个参数接受来自DataFrame分组这之后的值, 其余参数可自定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def my_mean(values): '''计算平均值 ''' n = len(values) # 获取数据条目数 sum = 0 for value in values: sum += value return(sum/n) # 调用自定义函数 df.groupby('year').lifeExp.agg(my_mean) # 计算全球平均预期寿命的平均值 与分组之后的平均值做差 def my_mean_diff(values,diff_value): '''计算平均值和diff_value之差 ''' n = len(values) sum = 0 for value in values: sum+=value mean = sum/n return(mean-diff_value) # 计算整个数据集的平均年龄 global_mean = df.lifeExp.mean() # 调用自定义函数 计算平均值的差值 df.groupby('year').lifeExp.agg(my_mean_diff,diff_value = global_mean)
1 2 # 按年计算lifeExp 的非零个数,平均值和标准差 df.groupby('year').lifeExp.agg([np.count_nonzero,np.mean,np.std])
1 2 3 4 5 6 7 8 9 10 df.groupby('year').agg({'lifeExp':'mean','pop':'median','gdpPercap':'median'}) # 也可以但单列传入多个聚合函数 df.groupby('year').agg({'lifeExp':['mean','max'],'pop':'median','gdpPercap':'median'}) # 对多个列进行相同的聚合方法 df.groupby('year')[['lifeExp','pop']].mean() # 从聚合之后返回的DataFrame中发现, 聚合后的列名就是聚合函数的名字, 可以通过rename进行重命名 df.groupby('year').agg({'lifeExp':'mean','pop':'median','gdpPercap':'median'}).rename(columns={'lifeExp':'平均寿命','pop':'人口','gdpPercap':'人均Gdp'}).reset_index()
transform 转换,需要把DataFrame中的值传递给一个函数, 而后由该函数”转换”数据。
aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量
用法: DataFrame.transform(func, axis=0, *args, **kwargs)
参数:
返回: DataFrame
1 2 3 4 5 6 7 8 9 10 11 df.transform(lambda x: x + 1) s.transform([np.sqrt, np.exp]) df.groupby('Date')['Data'].transform('sum') df['size'] = df.groupby('c')['type'].transform(len) def fill_na_mean(x): # 求平均 avg = x.mean() # 填充缺失值 return(x.fillna(avg)) total_bill_group_mean = tips_10.groupby('sex').total_bill.transform(fill_na_mean)
DataFrameGroupBy对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 调用groupby 创建分组对象 grouped = tips_10.groupby('sex') # 分组对象 grouped.groups # 获取每个分组的行索引 female = grouped.get_group('Female') # 根据传入的类别名称,获取对应的分组 for sex_group in grouped: #遍历grouped对象,查看sex_group数据类型 print(type(sex_group)) # 查看元素个数 print(len(sex_group)) # 查看第一个元素 print(sex_group[0]) # 查看第一个元素数据类型 print(type(sex_group[0])) # 查看第二个元素 print(sex_group[1]) # 查看第二个元素数据类型 print(type(sex_group[1])) break
Pandas 数据透视表 pivot_table()
pandas.pivot_table (data, values=None, index=None, columns=None, aggfunc=’mean’, fill_value=None, margins=False, dropna=True, margins_name=’All’, observed=False, sort=True)
index:行索引,传入原始数据的列名
columns:列索引,传入原始数据的列名
values: 要做聚合操作的列名
aggfunc:聚合函数
1 2 3 4 5 6 7 8 9 # 只聚合不显示原始数据 custom_info.pivot_table(index = '注册年月',values = '会员卡号',aggfunc = 'count') # D做聚合,A B行原始数据,C列原始数据,聚合方式为np.sum table = pd.pivot_table(df, values='D', index=['A', 'B'],columns=['C'], aggfunc=np.sum) table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],aggfunc={'D': np.mean,'E': np.mean}) table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],aggfunc={'D': np.mean,'E': [min, max, np.mean]})
Pandas datetime数据类型 Python中的datetime 1 2 3 4 5 6 7 8 9 10 from datetime import datetime now = datetime.now() now t1 = datetime.now() t2 = datetime(2020,1,1) diff = t1-t2 print(diff) print(type(diff))
Pandas中的datetime 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ebola['date_dt'] = pd.to_datetime(ebola['Date']) ebola.info() d = pd.to_datetime('2020-06-20') d.year #输出单个参数 d.day ebola['year'] = ebola['Date'].dt.year #不能直接.year ebola['month'],ebola['day'] = (ebola['Date'].dt.month,ebola['Date'].dt.day) #1. 加载数据,指定解析时间日期格式 crime = pd.read_csv('data/crime.csv',parse_dates=['REPORTED_DATE']) crime #2. 把时间日期列设置成索引 crime = crime.set_index('REPORTED_DATE', inplace=True) # 错误写法 crime.set_index('REPORTED_DATE', inplace=True) crime = crime.set_index('REPORTED_DATE') #3. 对时间日期的操作 crime.loc['2016-05-12'] #取出2016 5 12 这一天的报警记录 crime.loc['2015-03-01':'2015-03-15'].sort_index() crime.loc['2015-03-01 01:12':'2015-03-15 22'].sort_index() crime.between_time('2:00', '5:00') #查看每天的2点-5点报警记录 crime.at_time('5:47') #查看某个时刻报警记录 #4. 对crime数据进行分析 resample('Q') 是按照季度进行分组,统计每个季度报警数量 crime_quarterly = crime_sort.resample('QS')['IS_CRIME', 'IS_TRAFFIC'].sum() # QS是以每个季度的第一天作为索引 plot_kwargs = dict(figsize=(16,4), color=['black', 'blue'], title='丹佛犯罪和交通事故数据') crime_quarterly.plot(**plot_kwargs) # **是把plot_kwargs这个字典中的键值对作为参数传给plot函数,也可以直接把参数写在plot函数中