大数据_Spark入门基础
大数据_Spark入门基础
Spark是什么
Spark的概述
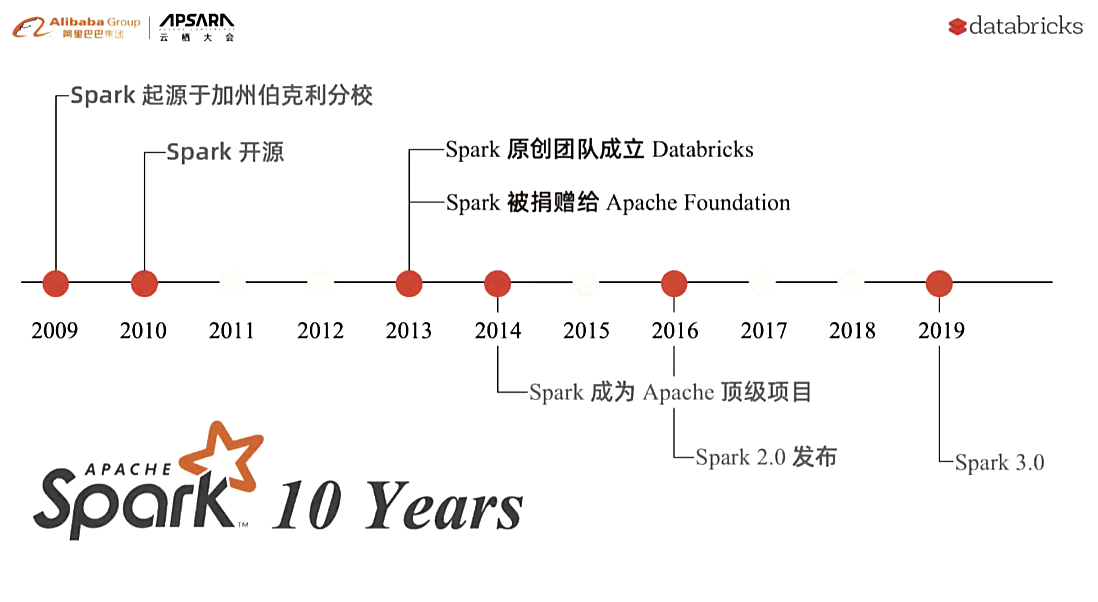
Apache Spark是用于大规模数据(large-scale data)处理的统一(unified)分析引擎。
2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、SparkStreaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
Spark的特点
Spark 使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点。
速度快
- Spark VS Hadoop
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD组成DAG有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce中间计算结果在HDFS磁盘上, 延迟大 | RDD中间运算结果在内存中 , 延迟小 |
| 运行方式 | Task以进程方式维护, 任务启动慢 | Task以线程方式维护, 任务启动快 |
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- Spark主要用于替代Hadoop中的MapReduce计算模型。存储依然可以使用HDFS,但是中间结果可以存放在内存中;
- Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
- Hadoop的基于进程的计算和Spark基于线程方式优缺点
- Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
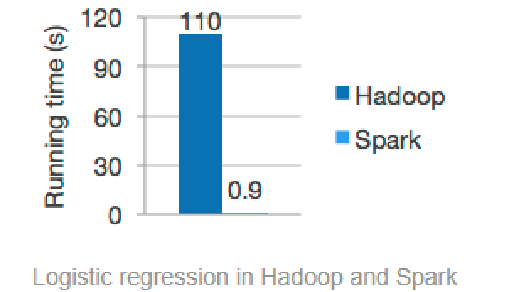
- Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- 其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
- 其二、Spark Job调度以DAG方式,并且每个任务Task执行以线程(Thread)方式,并不是像MapReduce以进程(Process)方式执行。
- Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
易使用
Spark 的版本已经更新到 Spark 3.2.0(截止日期2022.01.15)
为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本。
Spark可以使用Java、Scala、Python、R和SQL快速编写应用程序。
Spark提供80多个高级操作,使构建并行应用程序变得容易。可以从Scala、Python、R和SQL shell交互使用它。
通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,可以在一个应用中无缝地使用这些工具库。

运行在任何地方
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
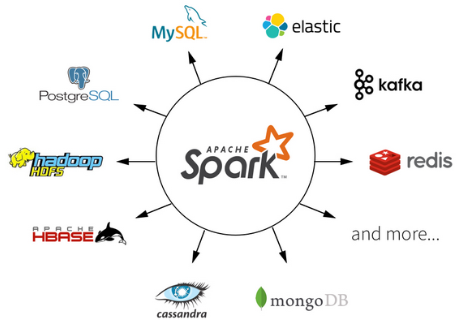
Spark框架结构
整个Spark 框架模块包含:Spark Coke、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上

Spark通信框架
整个Spark 框架通信采用模块:Netty
Spark 1.6,引入了Netty。
Spark 2.0之后,完全使用Netty,并把akka移除了。
Spark的安装
Spark Local 模式搭建
在本地使用单机多线程模拟Spark集群中的各个角色
安装包下载
目前Spark最新稳定版本:
3.2.0系列
https://spark.apache.org/docs/3.2.0/index.html
★注意1:
Spark3.0+基于Scala2.12
http://spark.apache.org/downloads.html
★注意2:
目前企业中使用较多的Spark版本还是Spark2.x,如Spark2.2.0、Spark2.4.5都使用较多,但未来Spark3.X肯定是主流,毕竟官方高版本是对低版本的兼容以及提升
http://spark.apache.org/releases/spark-release-3-0-0.html
将安装包上传并解压
说明: 只需要上传至node1即可, 以下操作都是在node1执行的
1 | cd /export/software |
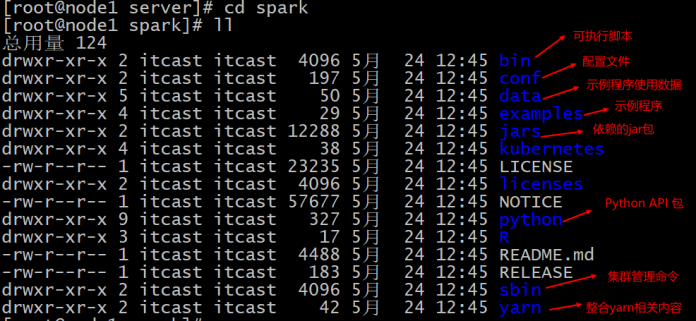
测试
Spark的local模式, 开箱即用, 直接启动bin目录下的spark-shell脚本
1 | cd /export/server/spark/bin |
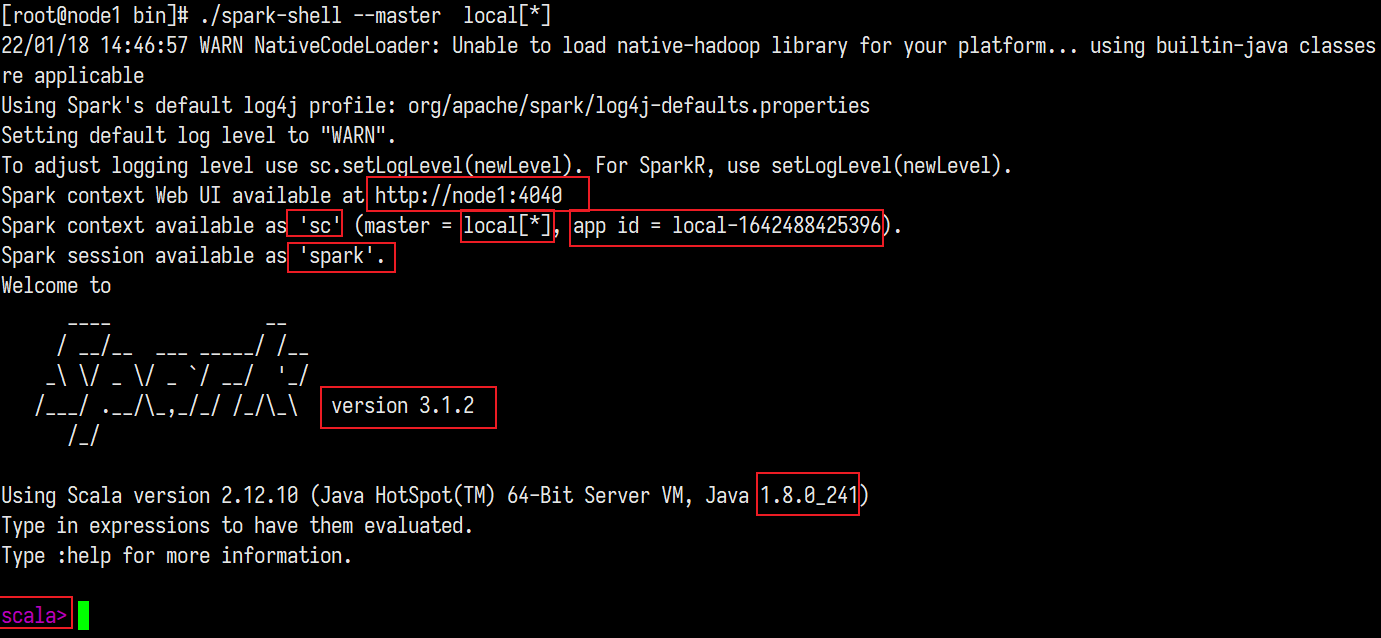
sc:SparkContext实例对象:
spark:SparkSession实例对象
4040:Web监控页面端口号
- Spark-shell说明:
- 1.直接使用./spark-shell
- 表示使用local 模式启动,在本机启动一个SparkSubmit进程
- 2.还可指定参数 –master,如:
- spark-shell –master local[N] 表示在本地模拟N个线程来运行当前任务
- spark-shell –master local[*] 表示使用当前机器上所有可用的资源
- 3.不携带参数默认就是
- spark-shell –master local[*]
- 4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
- ./spark-shell –master spark://node01:7077,node02:7077
- 5.退出spark-shell 使用 :
- quit
- 1.直接使用./spark-shell
PySpark的安装
- PySpark是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
- Spark是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
安装Anaconda
下载安装&简单配置
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
1 | cd /export/software |
说明:
- profile
- 其实看名字就能了解大概了, profile 是某个用户唯一的用来设置环境变量的地方, 因为用户可以有多个 shell 比如 bash, sh, zsh 之类的, 但像环境变量这种其实只需要在统一的一个地方初始化就可以了, 而这就是 profile.
- bashrc
- bashrc 也是看名字就知道, 是专门用来给 bash 做初始化的比如用来初始化 bash 的设置, bash 的代码补全, bash 的别名, bash 的颜色. 以此类推也就还会有 shrc, zshrc 这样的文件存在了, 只是 bash 太常用了而已.
请将当前连接node1的节点窗口关闭,然后重新打开,否则无法识别
使用anaconda之后, 在linux的界面中出现 base 字段内容, 主要的原因是 anaconda在安装之后, 会自动创建一个base的沙箱环境, 同时在启动会话的时候, 自动进入到基础环境中,如何屏蔽呢?
1 | 修改.bashrc 配置文件, 在文件默认添加一个: conda deactivate |
Anaconda相关组件
1 | 安装包:pip install xxx,conda install xxx |
conda命令及pip命令
1 | conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。 |
安装PySpark
所有节点都需要安装pySpark的
三个方法:
直接pip
pip install pysparkpip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行):
pip install pyspark[sql]
创建Conda环境安装PySpark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15从终端创建新的虚拟环境
conda create -n pyspark_env python=3.8
创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看
conda env list
现在使用以下命令激活新创建的环境:
source activate pyspark_env
或者
conda activate pyspark_env
如果报错: CommandNotFoundError: Your shell has not been properly configured to use 'conda deactivate'.切换使用 source activate
可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。
pip install pyspark
或者,可以从 Conda 本身安装 PySpark:
conda install pyspark手动下载安装
将spark对应版本下的python目录下的pyspark复制到anaconda的
Library/Python3/site-packages/目录下即可。请注意,PySpark 需要JAVA_HOME正确设置的Java 8 或更高版本。如果使用 JDK 11,请设置-Dio.netty.tryReflectionSetAccessible=true,Arrow相关功能才可以使用。
扩展:
conda虚拟环境命令
查看所有环境conda info --envs
新建虚拟环境conda create -n myenv python=3.6
删除虚拟环境conda remove -n myenv --all
激活虚拟环境conda activate myenvsource activate base
退出虚拟环境conda deactivate myenv
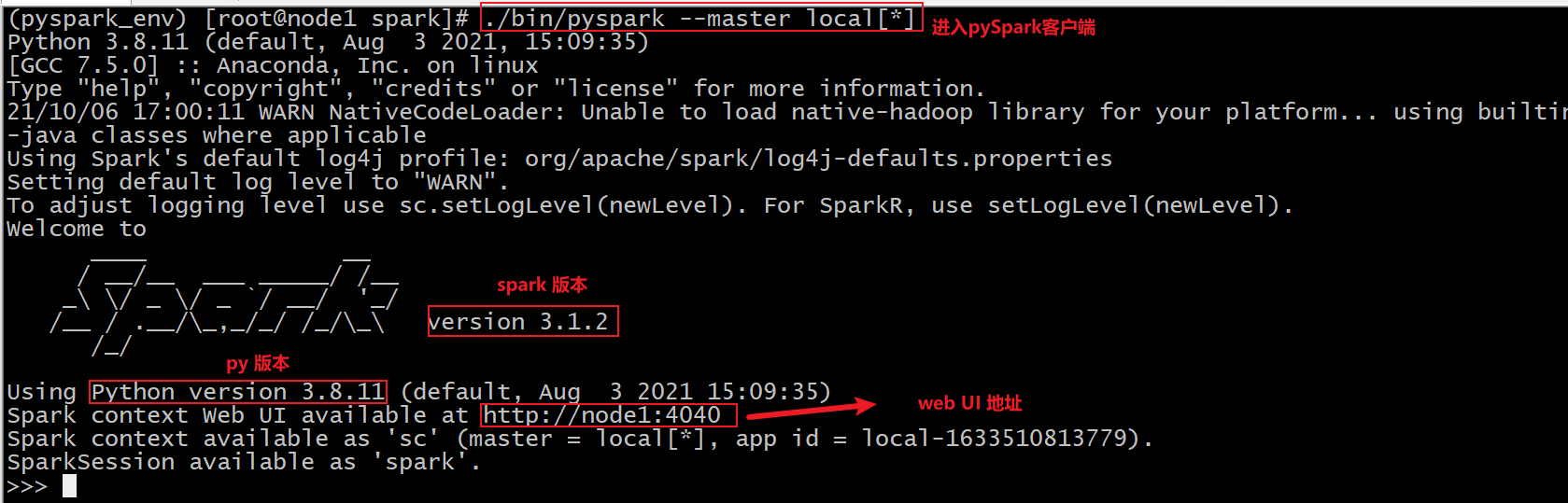
测试PySpark shell方式
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
1 | bin/pyspark --master local[*] |
Spark On Yarn搭建
概述
- Spark On Yarn的本质?
- 将Spark任务的pyspark文件,经过Py4J转换,提交到Yarn的JVM中去运行
- Spark On Yarn需要啥?
- 1.需要Yarn集群:已经安装了
- 2.需要一台机器上有提交工具:spark-submit命令–在spark/bin目录
- 3.需要上面的机器上有被提交的PySpark代码:Spark任务的文件,如spark/examples/src/main/python/pi.py中有示例程序,或我们后续自己开发的Spark任务)
- 4.需要其他依赖jar:Yarn的JVM运行PySpark的代码经过Py4J转化为字节码,需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
修改配置
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
spark-env.sh
1 | cd /export/server/spark/conf |
整合&关闭资源检查
整合历史服务器MRHistoryServer并关闭资源检查
整合Yarn历史服务器并关闭资源检查
在【$HADOOP_HOME/etc/hadoop/yarn-site.xml】配置文件中,指定MRHistoryServer地址信息,
在node1上修改, 修改成下面的XML:
1 | cd /export/server/hadoop/etc/hadoop |
1 | <configuration> |
同步到全部机器
1 | cd /export/server/hadoop/etc/hadoop |
配置HistoryServer
在【$SPARK_HOME/conf/spark-defaults.conf】文件增加SparkHistoryServer地址信息:
1 | # 进入配置目录 |
修改内容如下:

同步到全部机器
1 | cd /export/server/spark/conf |
配置依赖Spark Jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
1 | # hdfs上创建存储spark相关jar包目录 |
启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer
1 | # 启动HDFS和YARN服务,在node1执行命令 |
Spark HistoryServer服务WEB UI页面地址:http://node1:18080/
Pyspark初体验
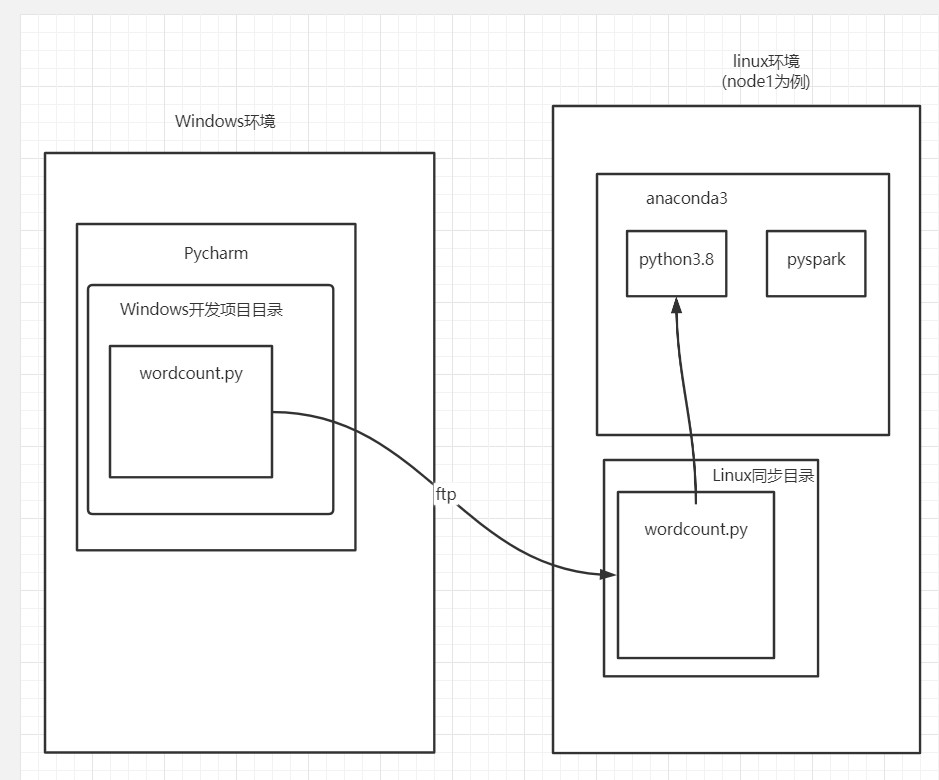
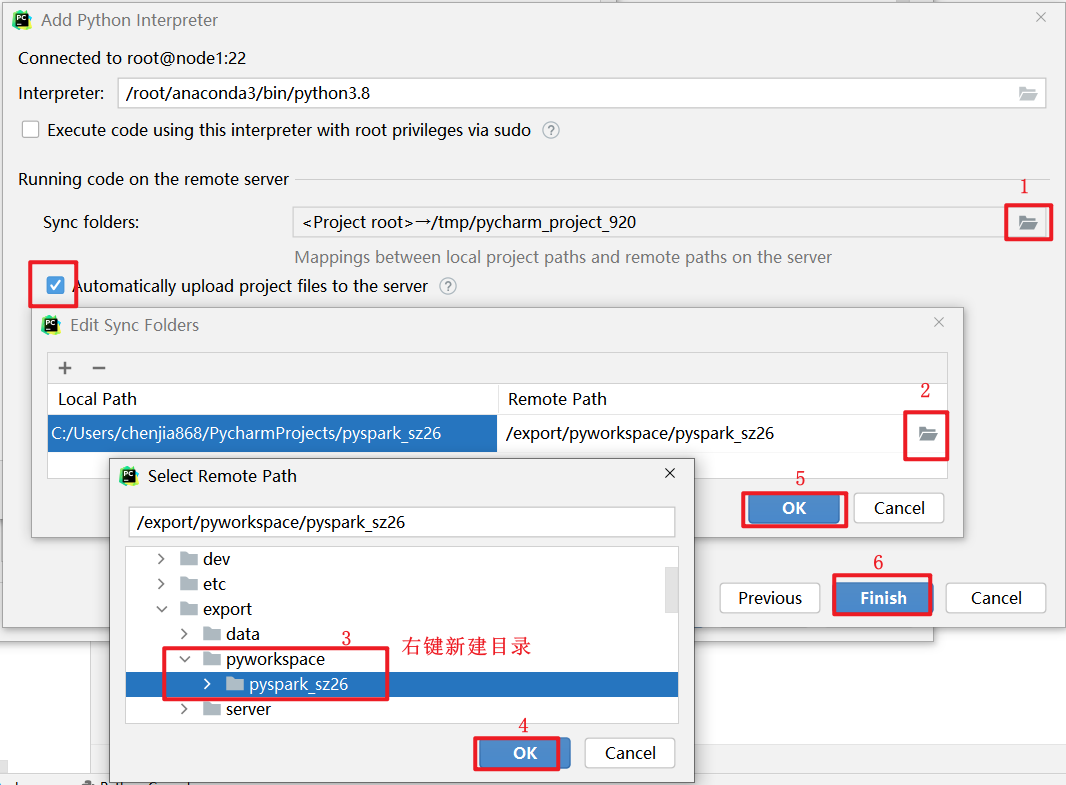
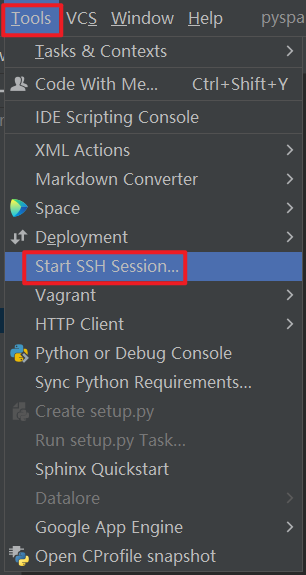
Pycharm连接SSH
本文使用的pycharm2021专业版, 社区版部分功能没有, 注意.
原理图
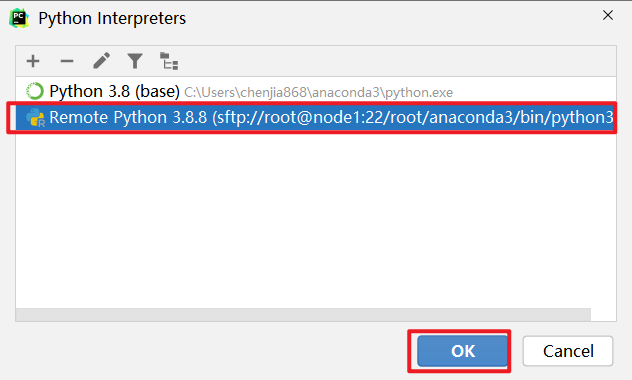
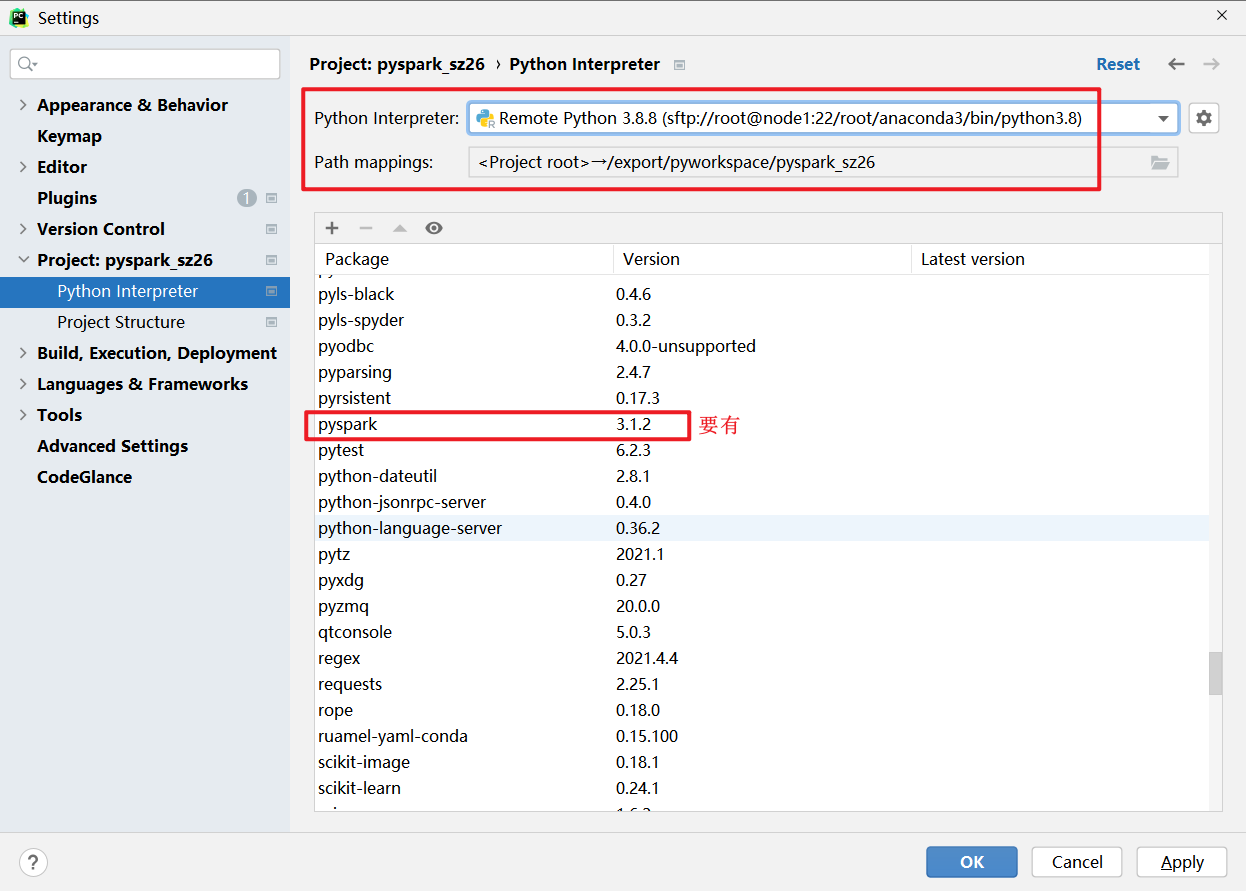
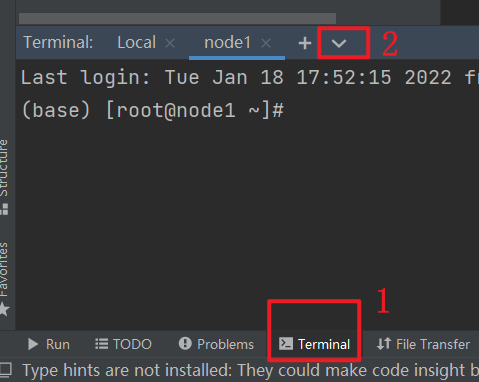
连接操作
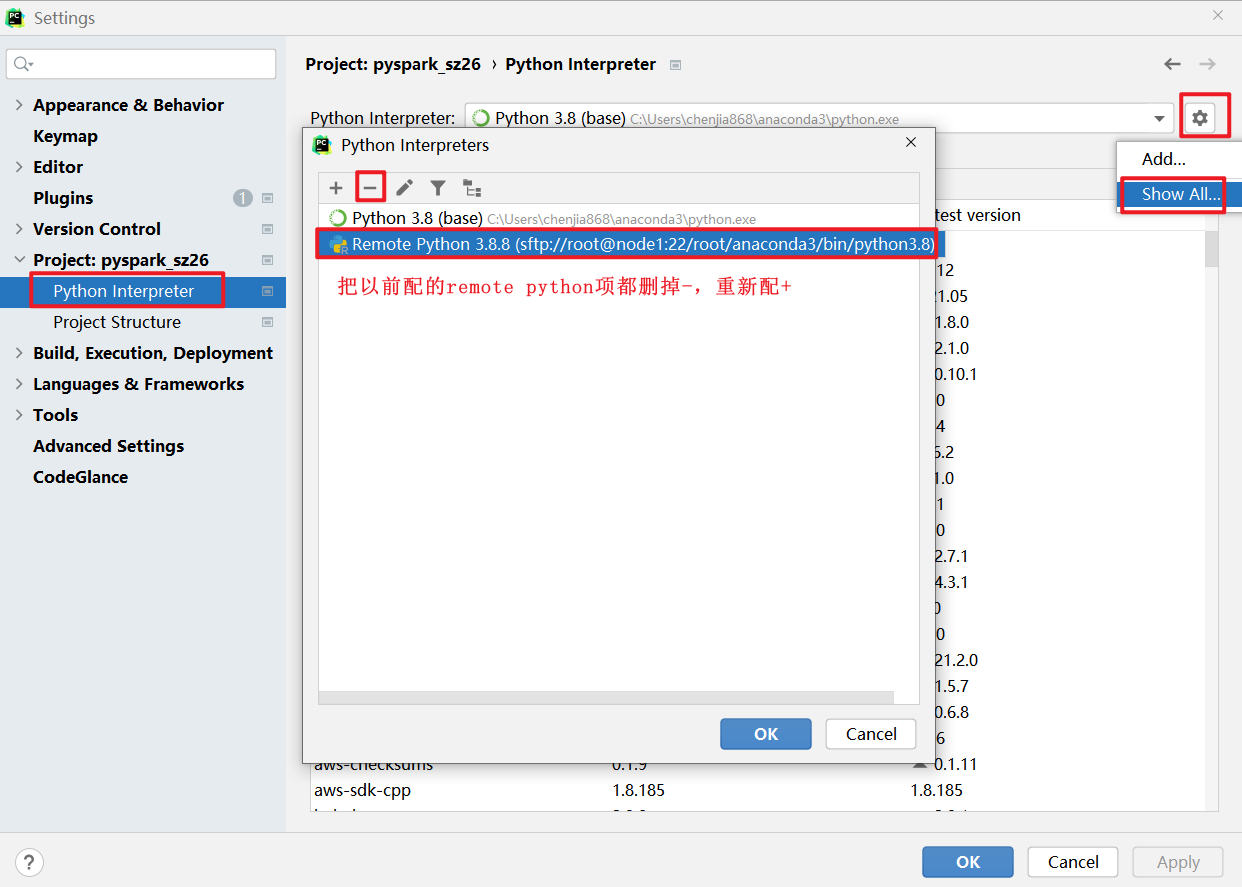
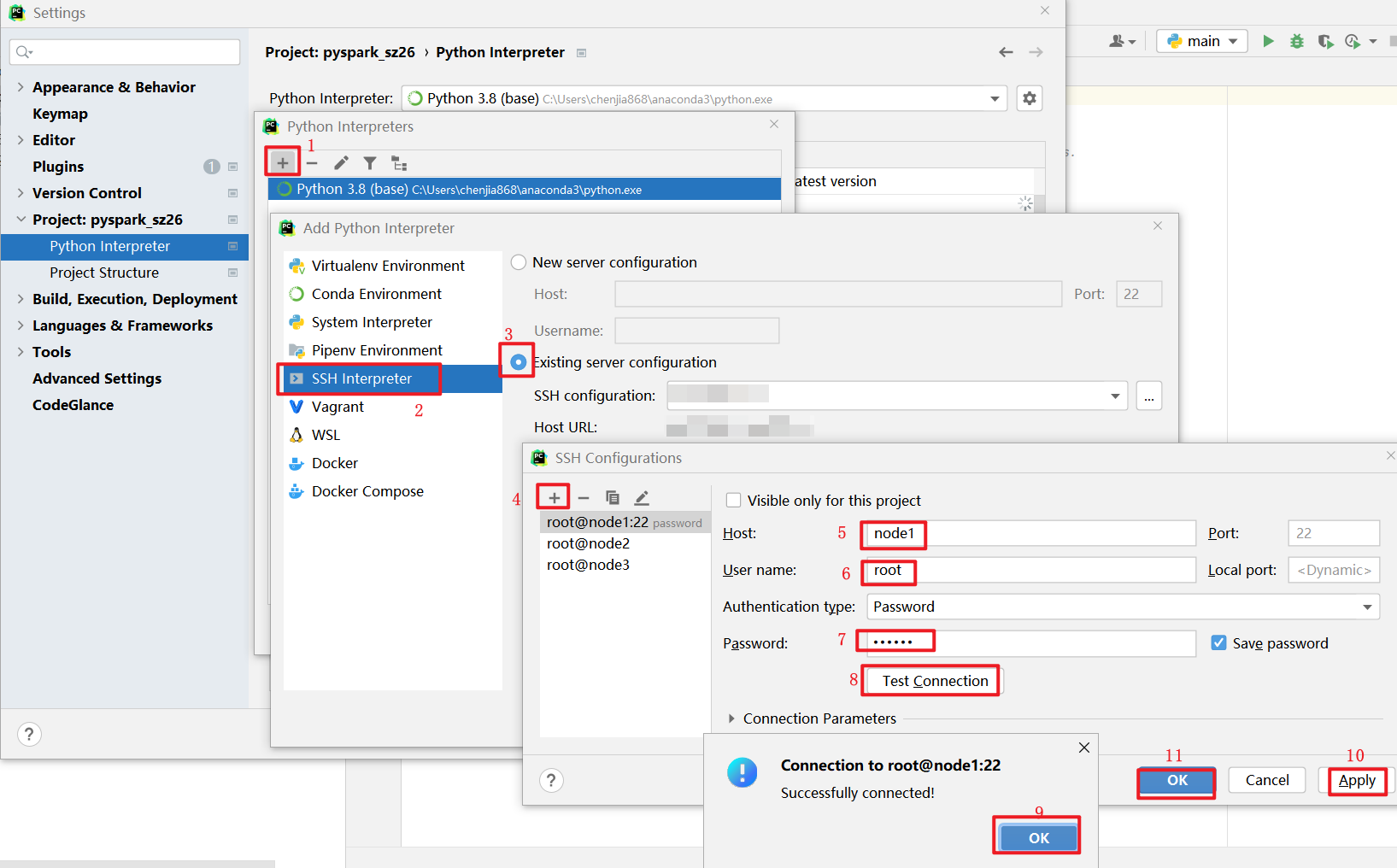
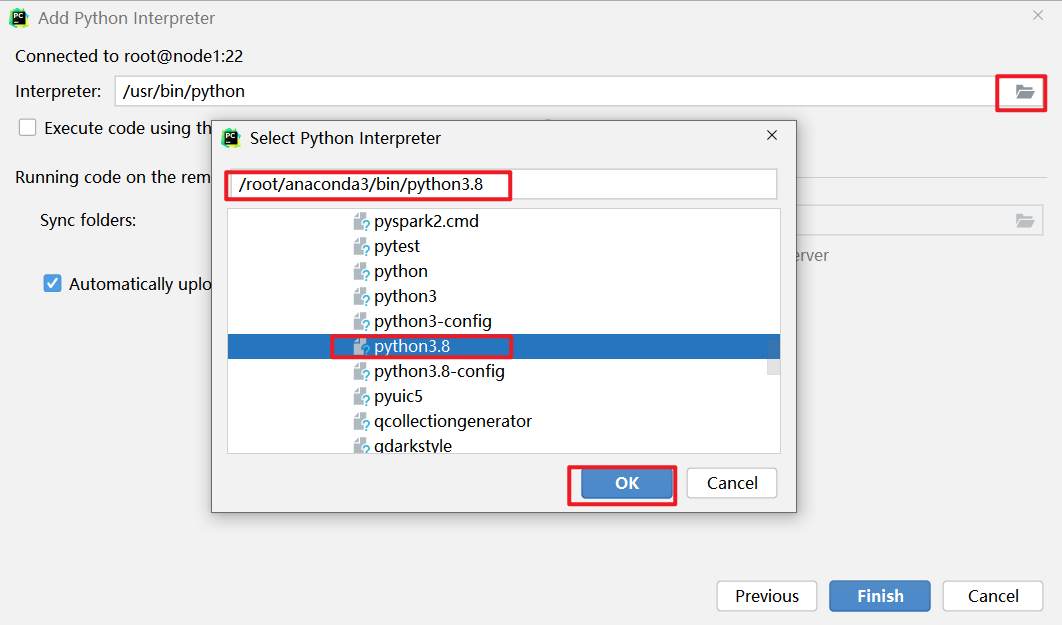
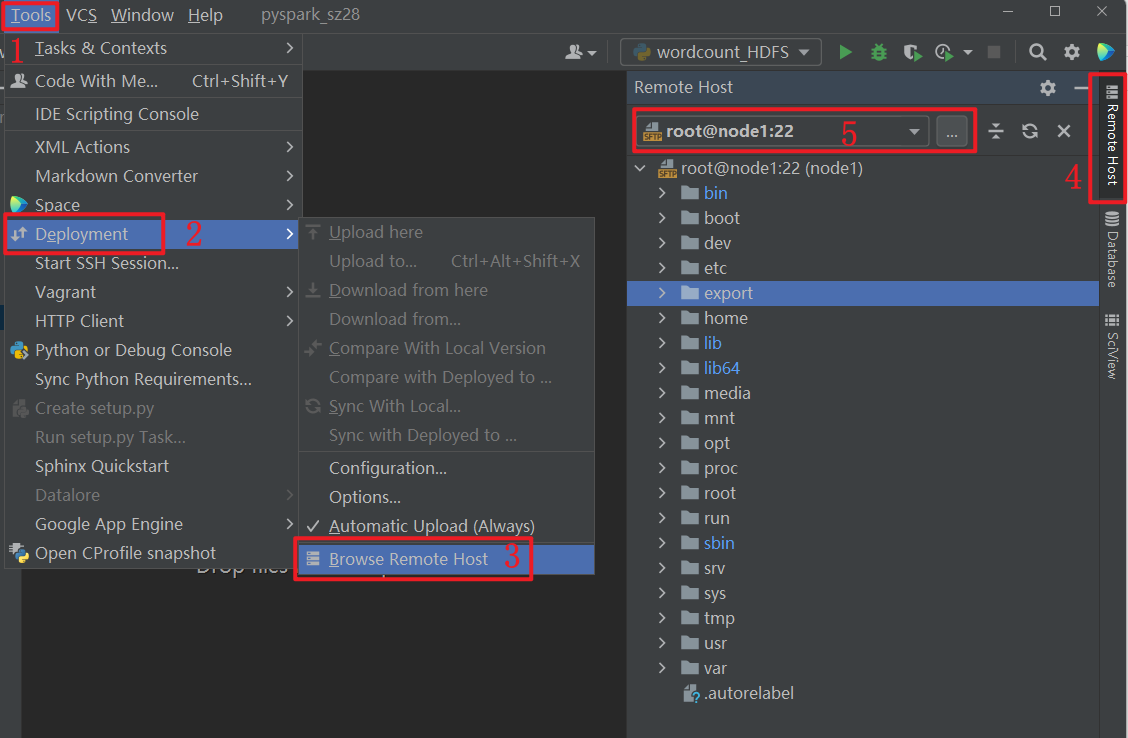
初始化

运行wordcount程序

原理图

代码
需要等待pycharm初始化索引后操作
测试文本文件
1 | Hello World |
- 本地创建一个
words.tx - 往HDFS传一个
hdfs dfs -put word.txt /pydata/words.txt hdfs dfs -ls /pydata
本地操作代码
1 | # -- coding: utf-8 -- |
HDFS操作代码
1 | # -- coding: utf-8 -- |
spark_submit操作代码
1 | # -- coding: utf-8 -- |
1 | spark-submit --master local[*] /tmp/pycharm_project_594/PySpark-SparkBase_3.1.2/main/wordcount_spark_submit.py file:///tmp/pycharm_project_594/PySpark-SparkBase_3.1.2/data/words.txt |
排错
如果提示错误JAVA HOME is not set
1 | vim /root/.bashrc |
profile文件是在用户登录的时候进行初始化的,/etc/profile和
/.profile分别对应所有用户和单个用户。而/.bashrc文件,则是在每次启动一个shell的时候,对环境进行初始化。即etc是全局的,但是远程python只读取.bashrc
Spark On Yarn运行
Spark on Yarn的本质
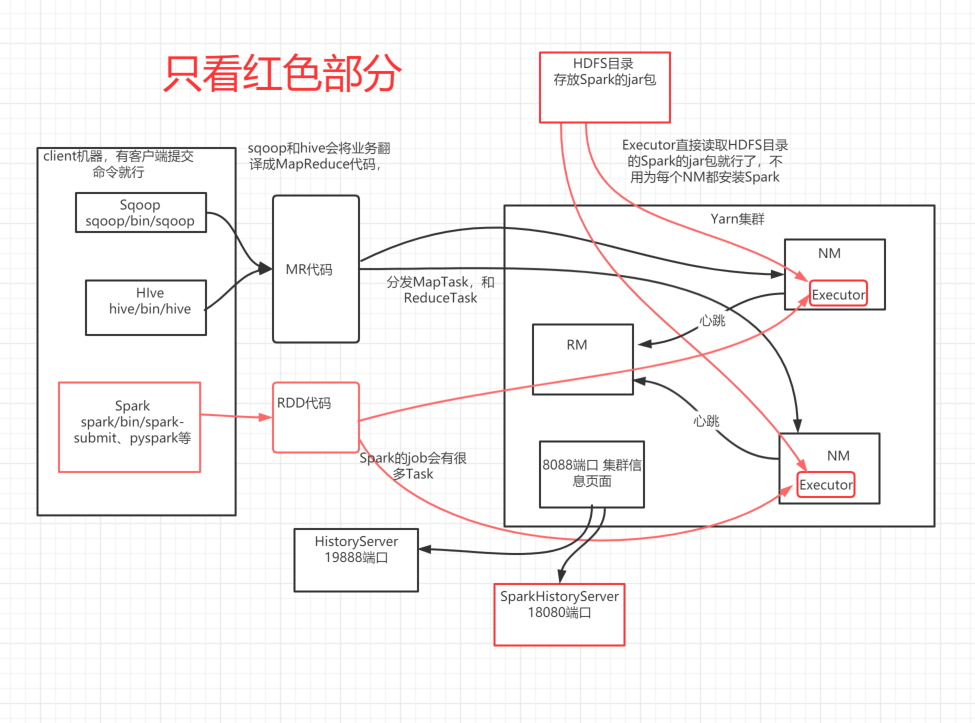
Spark应用架构
只有Spark应用跑起来才有,如果程序退出,则消失。
就是Spark运行时架构。
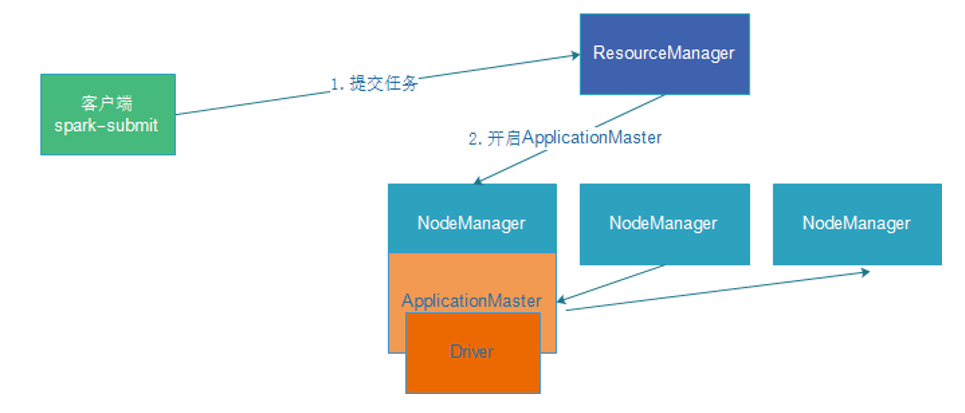
从图中可以看到一个Spark Application运行到集群上时,由两部分组成:【一个driver】和【多个Executor】。
1、Driver Program
- 是一个JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
- 一个SparkApplication仅有【1】个;
2、Executors
- 运行JVM Process,相当于一个线程池,其中有很多线程,每个线程运行【1】个Task任务,一个Task运行需要【1】 Core CPU,所以Executor中线程数就等于CPU Core核数;
- 一个Spark Application可以有【多】个;
Driver中如何由job拆分成task的过程
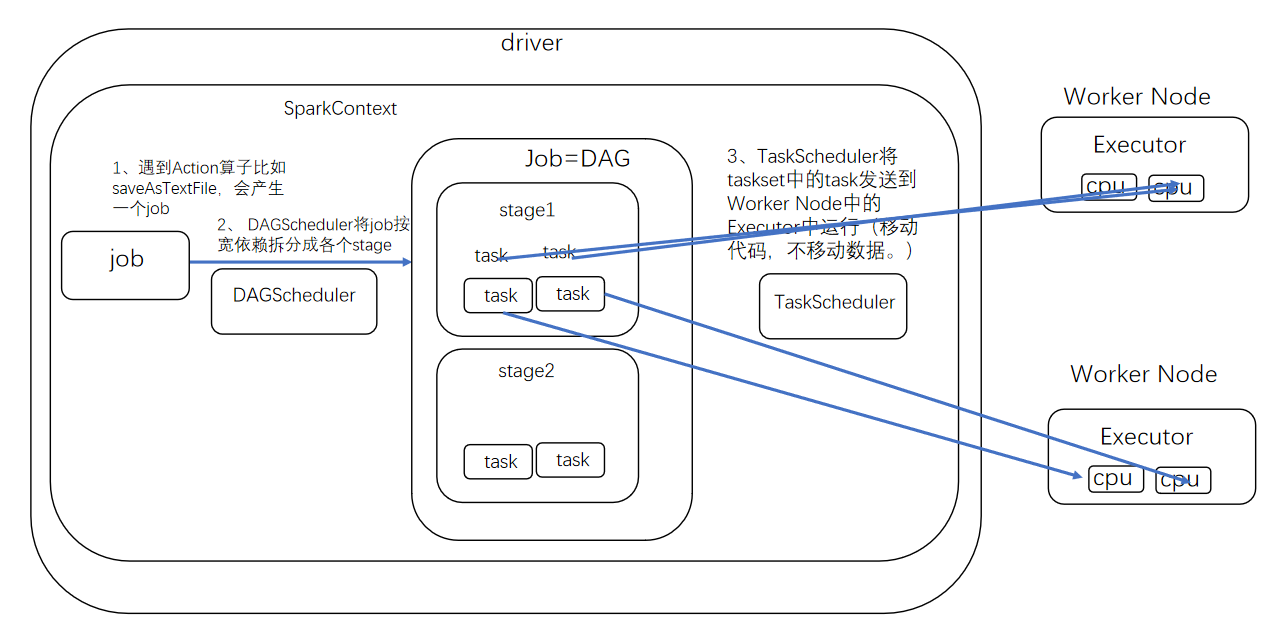
运行模式概述
Spark On Yarn 有两种模式, Client和Cluster
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里。
client模式:学习测试时使用,开发不用,了解即可
- Driver运行在Client上的SparkSubmit进程中
- 应用程序运行结果会在客户端显示
cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中
- 应用的运行结果不能在客户端client显示
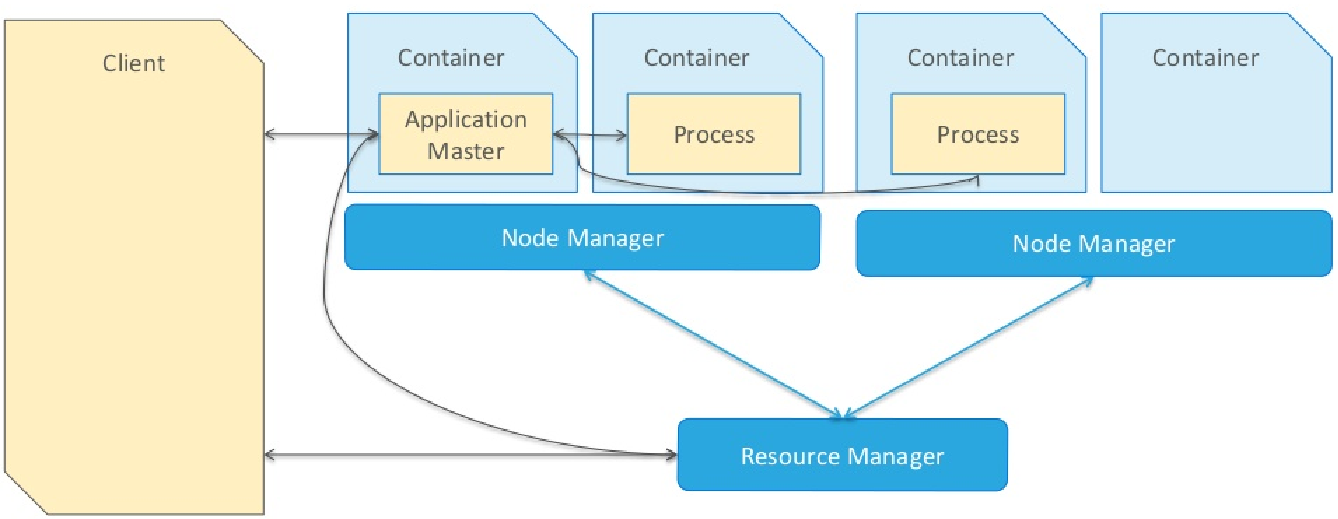
当一个MR应用提交运行到Hadoop YARN上时
包含两个部分:应用管理者AppMaster和运行应用进程Process(如MapReduce程序MapTask和ReduceTask任务)
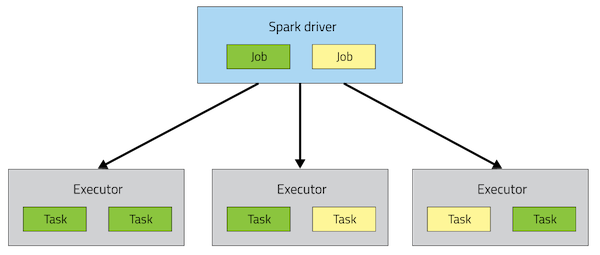
当一个Spark应用提交运行在集群上时,
应用架构有两部分组成:Driver Program(资源申请和调度Job执行)和Executors(运行Job中Task任务和缓存数据),都是JVM Process进程
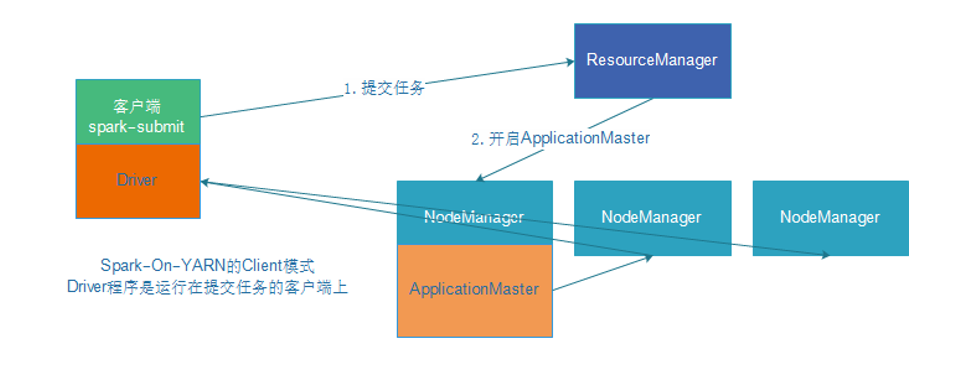
而Driver程序运行的位置可以通过–deploy-mode 来指定,
值可以是:
1.client:表示Driver运行在提交应用的Client上(默认)
2.cluster:表示Driver运行在集群中(Standalone:Worker,YARN:NodeManager)
Client运行模式
DeployMode为Client,表示应用Driver Program运行在提交应用Client主机上
跑个代码
1 | SPARK_HOME=/export/server/spark |
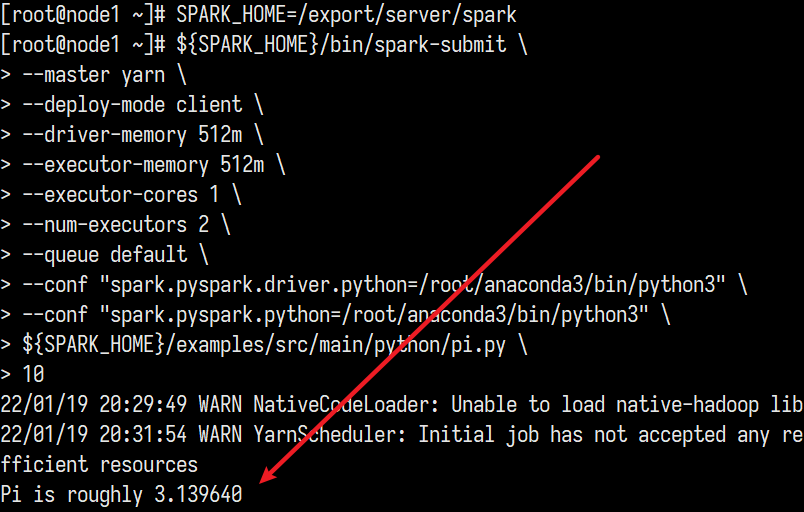
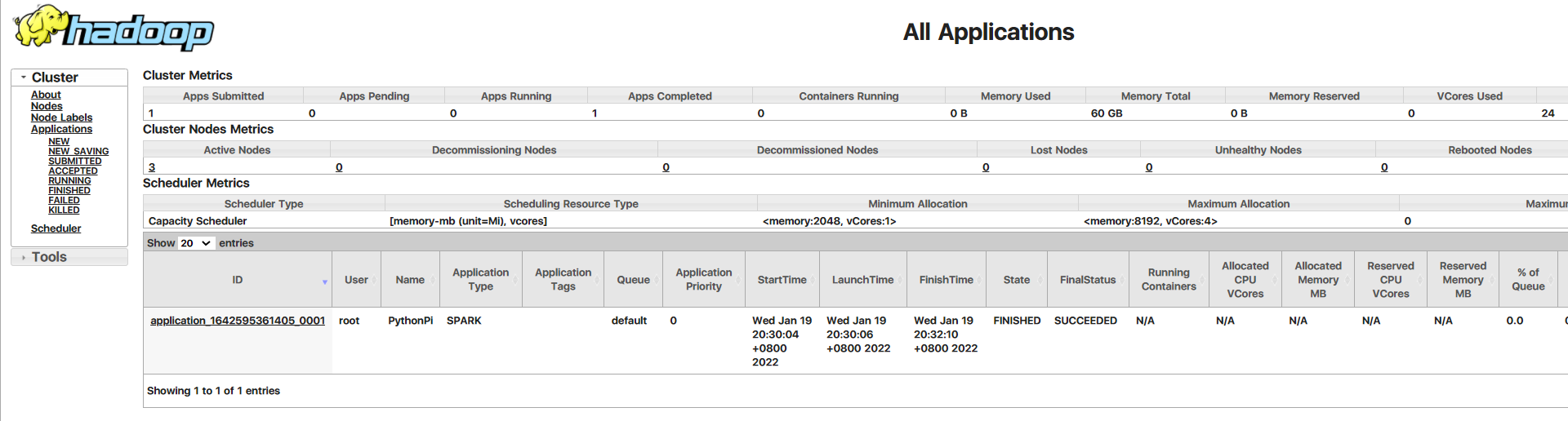
结果查看:http://node1:8088/cluster
Cluster运行模式
DeployMode为Cluster,表示应用Driver Program运行在集群从节点某台机器上
跑个代码
1 | {SPARK_HOME}/bin/spark-submit \ |
结果查看:http://node1:8088/cluster
Spark相关参数
1 | (base) [root@node1 bin]# ./spark-submit --help |
常用命令:
公共参数
–master :Spark使用什么资源管理器来分配【CPU】和【内存】资源,后面可以跟【spark://node1:7077】,【yarn】 ,【local[*]】等,企业中用的最多的是【yarn】
–deploy-mode :只有【2】个值,【client】和【cluster】,区别是【Driver】进程运行在哪里
–name :给Spark程序起一个名字,后期可以在WEBUI(端口是【4040】)页面上看到
-class 包名.类名 需要跟上xx.jar:固定用法,需要配合spark-submit使用的,意思是提交jar包中的类的main方法程序。
比如
1
2
3
4
5
6SPARK_HOME=/export/server/spark
{SPARK_HOME}/bin/spark-submit \
--master local[*] \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.1.2.jar \
10
Driver进程相关参数:
- –driver-memory 申请【Driver】进程的【内存】有大多。
- –driver-cores :仅当是以–deploy-mode 是【cluster】是才有意义。表示【Driver】进程申请几个【核】
Executor进程相关参数
- –total-executor-cores :仅当用Spark 的【standalone】方式才有意义,表示所有的executor一共申请多少个【核数】
- –executor-cores :仅当Spark 的【standalone】方式以及【yarn】方式才有意义,表示每个executor进程申请几个【核数】。yarn默认是1个,standalone默认是Worker的全部的core。企业中一般指定为3-5个,通常是4.
- –num-executors :仅当是【Yarn】时才有意义,表示一共申请多少个【Executor】。
- –executor-memory 申请的【Executor】的【内存】有多大。Executor进程中的一个core可以支配3-5G的内存,如果是3G,executor-memory 最好设为executor-cores*3
- –queue 就是用来隔离CPU和内存资源的。每个队列中都包含了指定容量的CPU和内存
常见问题
为什么Spark On Yarn 时通过ApplicationMaster去向ResourceManager申请启动Executors,而不是通过Driver去干这些事情?
- 因为,回顾在standalone集群模式中,Driver向Master申请Worker的资源用于启动Executor,而同样的,在Yarn集群模式中,Spark应用需要向ResourceManager申请NodeManager的资源用于启动Executor,这个职责可以让ApplicationMaster去做,而不是让Driver去做,可以让Driver更轻松,达到解耦的目的。
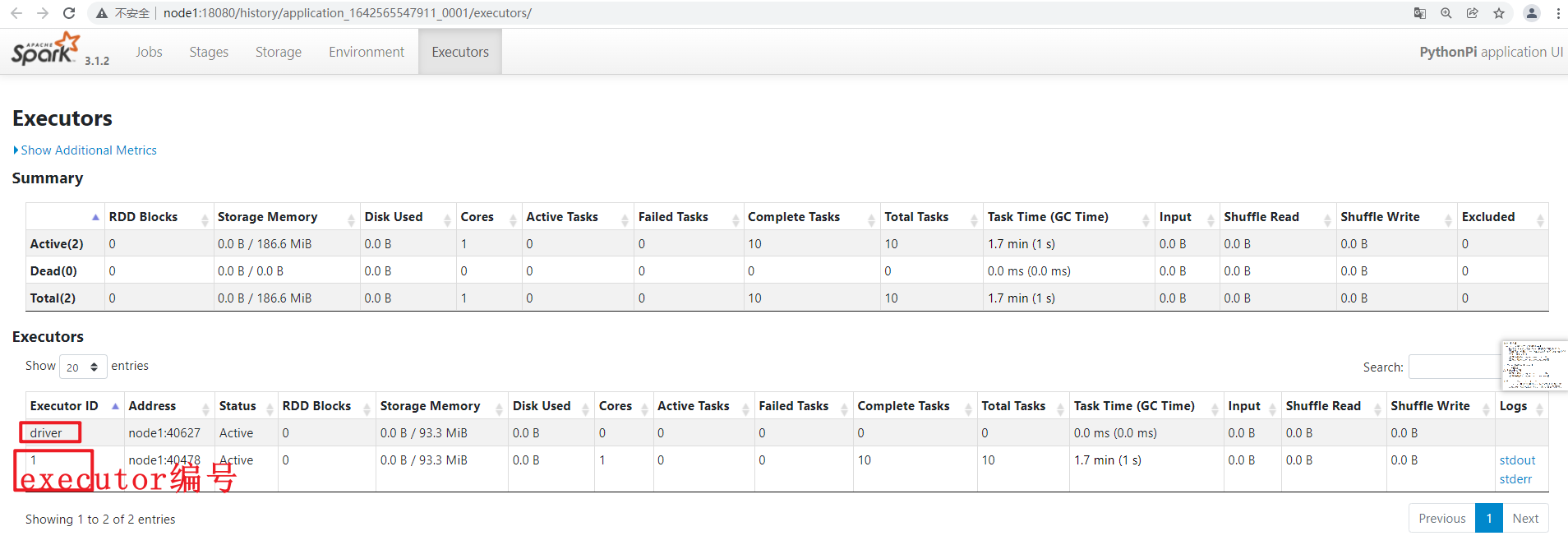
为什么用yarn-client方式可以在提交的机器上看到打印的结果,但是用yarn-cluster看不到,需要去yarn的历史日志才能看到?
- 因为用yarn-client方式,Driver进程就是启动在Client上,打印的结果显示在Client机器上。但是用yarn-cluster运行Spark程序时,Driver是某台随机的NodeManager,它就算打印了,也不会显示在当前的提交机器上,但是yarn的历史日志服务,会收集所有yarn节点的日志,所以可以在yarn的历史日志页面(yarn的node1:8088页面,点击logs,再跳转19888端口页面)中查看到程序的结果。
为什么企业中都使用-yarn-cluster模式?
- 1、因为这种方式,使得Driver向Executor们的通信都在同一个集群的网段中,通信效率高。而反之yarn-client模式的Driver在提交的网段,Executor们在yarn集群的网段,2个网段可能不一样,通信效率低。
- 2、一般在企业中提交的机器就那么1-2台,如果大家都在同一台机器上用client模式运行各自的Spark应用,那么会造成所有的Driver进程都启动在这台机器上,造成这台机器的负担很重,造成所有的任务都受到影响。而随机的空闲的WorkerNode分散了各个Driver,负载均衡。





