Logstash学习_基础
Logstash学习_基础
任务
1.理解logstash在ELK中的“位置”:数据清洗与格式化,也可以作为收集器,使用java编写,较为重量级,丰富的插件,具有较强的处理能力(https://www.elastic.co/guide/en/logstash/6.8/introduction.html)
2.logstash安装(使用tar压缩包安装,不需要安装java环境)https://www.elastic.co/guide/en/logstash/7.10/installing-logstash.html#installing-binary
3.认识config目录下的jvm.options的内容:修改Xmx和Xms值适合自己的虚拟机或服务器;了解logstash.yml和pipeline.yml,两个文件分别是logstash的主配置文件和加载配置文件的配置(类似filebeat,但logstash正式的启动方式原本就具备配置文件的加载文件,但启动动态加载需要在logstash.yml里面配置);pipeline.yml里面写的是每一个外部的配置文件和指定多少个线程,当这两个配置文件完成配置后,启动logstash就只需要bin/logstash,测试时采用 bin/logstash -f xxx.conf 来指定配置文件
4.了解logstash的pipeline的工作流程(每一个配置文件就是一个管线,即pipeline)https://www.elastic.co/guide/en/logstash/7.10/pipeline.html,其配置文件也遵循这个编写顺序:
i: input与output,使用beats插件,从filebeat获取输入数据(https://www.elastic.co/guide/en/logstash/7.10/plugins-inputs-beats.html), stdout作为输出(需检验)(https://www.elastic.co/guide/en/logstash/7.10/plugins-outputs-stdout.html)
ii: filter,对数据进行切割、格式化、字段重命名计算等
a. 了解mutate插件:使用stdin作为input,用mutate去给输入的信息增加字段:add_field,以及删除字段:remove_field
b. 了解date插件:使用stdin作为input,用date插件处理输入的时间字符串,例如“2022-05-01 00:00:00”,输出到logdatetime字段(需检验)
c. 了解drop插件:在上一步的基础上,输入不匹配的时间字符串,导致date插件失败,实现手动丢弃丢弃该条数据(需检验)
Logstash概述
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
logstash常用于日志系统中做日志采集设备,最常用于ELK中作为日志收集器使用
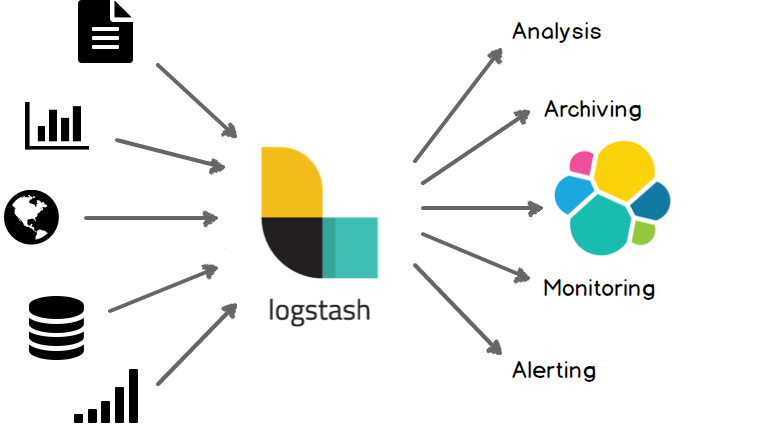
集中、转换和存储你的数据,是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储
Logstash基本架构
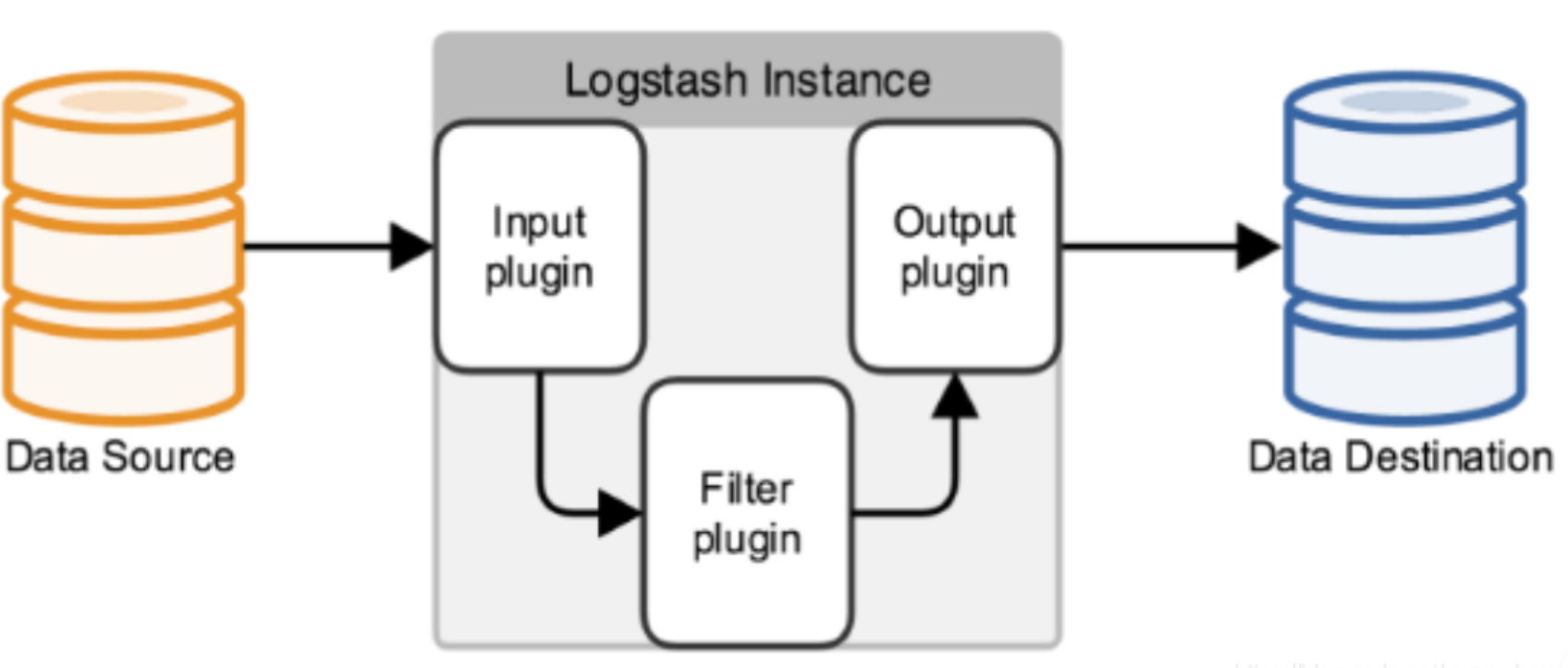
logstash的基本流程架构:input | filter | output 如需对数据进行额外处理,filter可省略。
安装Logstash
官方下载zip包直接解压到机器里面, 不做赘述
由于不可抗力, 此处我用的是7.6.1版本
目录结构如下
简单配置Logstash
jvm.options
config/jvm.options文件, 配置内存大小优化 可根据服务器的性能进行配置
1 | ## JVM配置 |
logstash.yml
配置文件config/logstash.yml是Logstash的主配置文件,详解如下(7.x版本)
1 | #使用分层表单来设置管道的批处理大小和批处理延迟 |
pipeline.yml
一个 logstash 实例中可以同时进行多个独立数据流程的处理工作
之前用户只能通过在单机运行多个 logstash 实例或者在配置文件中增加大量 if-else 条件判断语句来解决
使用 multiple pipeline 只需要将不同的 pipeline 在 config/pipeline.yml中定义好即可
例子
1 | - pipeline.id: apache |
其中apache和nginx作为独立的 pipeline 执行,而且配置也可以独立设置,互不干扰。
pipeline.yml的引入极大地简化了 logstash 的配置管理工作
简单input与output
在/config新建一个filebeat_std.conf
1 | input { |
然后在filebeat的根目录下再新建一个test07_filebeat.yml\
1 | # 输入 |
当时这里碰到了一个小问题 由于手滑在写
output.logstash的时候上面的output.file:一行忘记删了根目录就出现了
filebeat.1 filebeat.2这种文件, 询问过何老师后发现这是由于它输出的文件是默认没改的,可能就是输出到相对路径./filebeat,然后,它发现里面有一个filebeat(可执行文件);接着它就把这个filebeat当做日志,给滚动命名了
先跑logstash再跑filebeat 顺序不能颠倒
分别再二者的根目录执行
1 | ./bin/logstash -f ./config/filebeat_std.conf |
1 | ./filebeat -e -c test07_filebeat.yml |
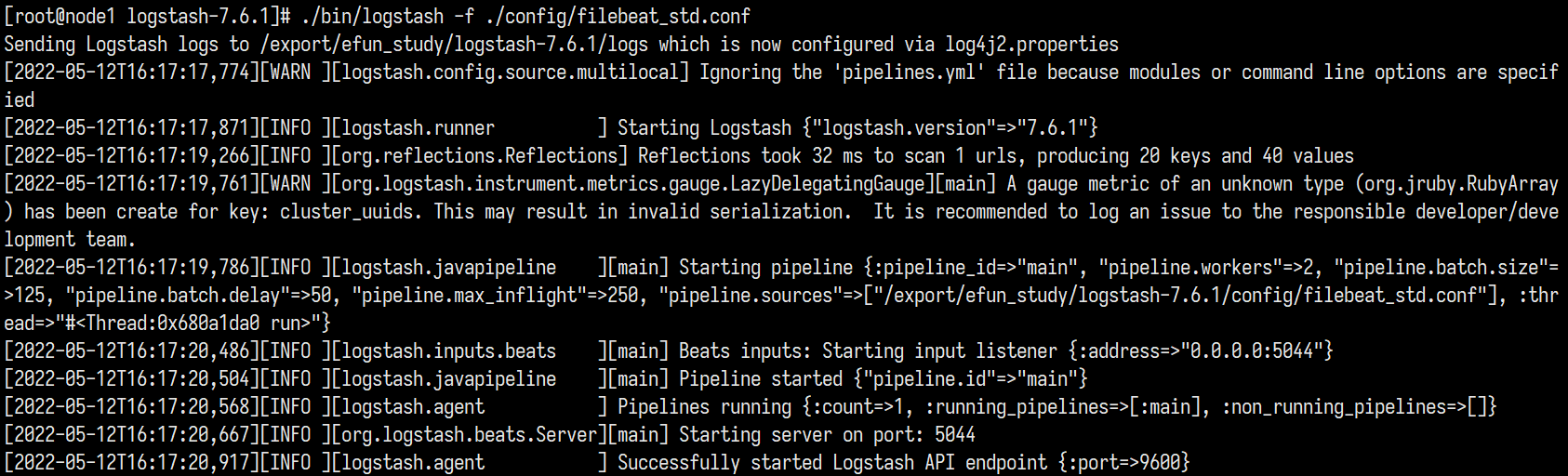
初始化logstash成功
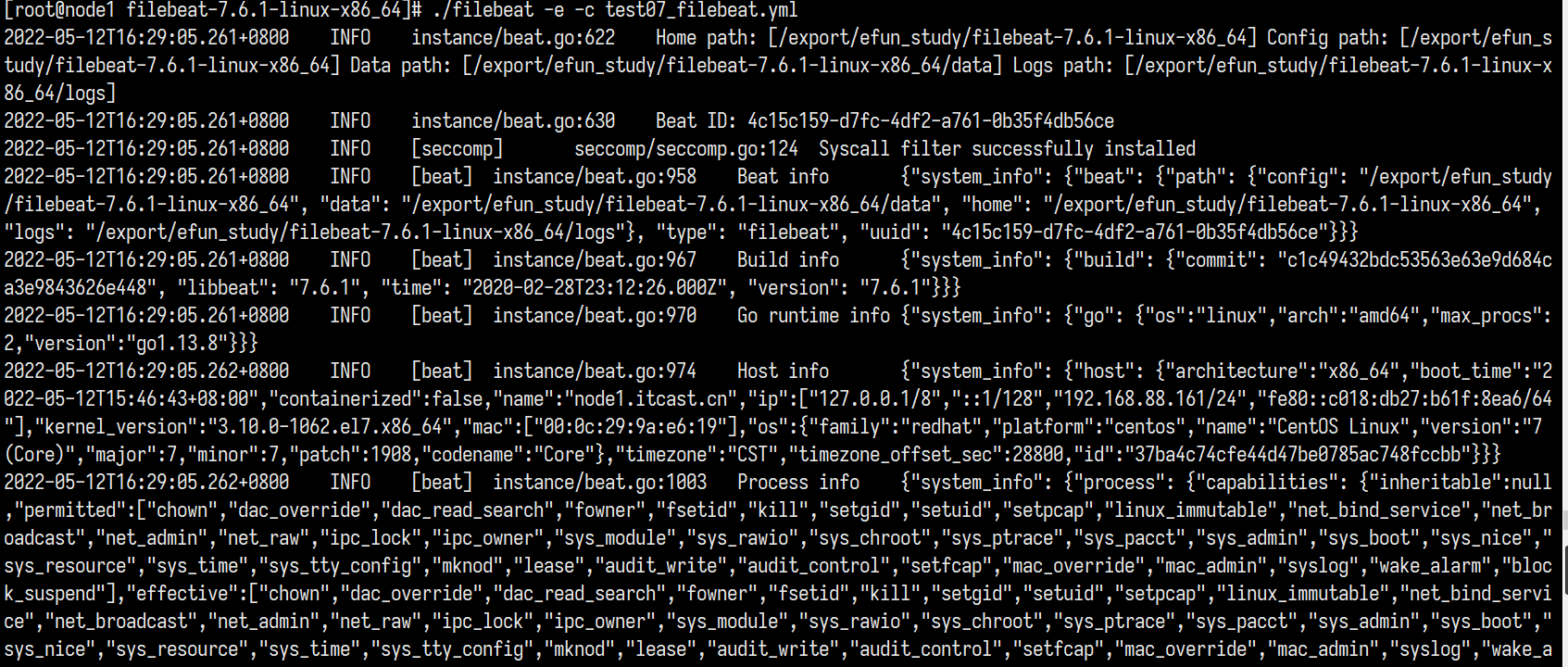
和以前一样filebeat 正常启动并收集
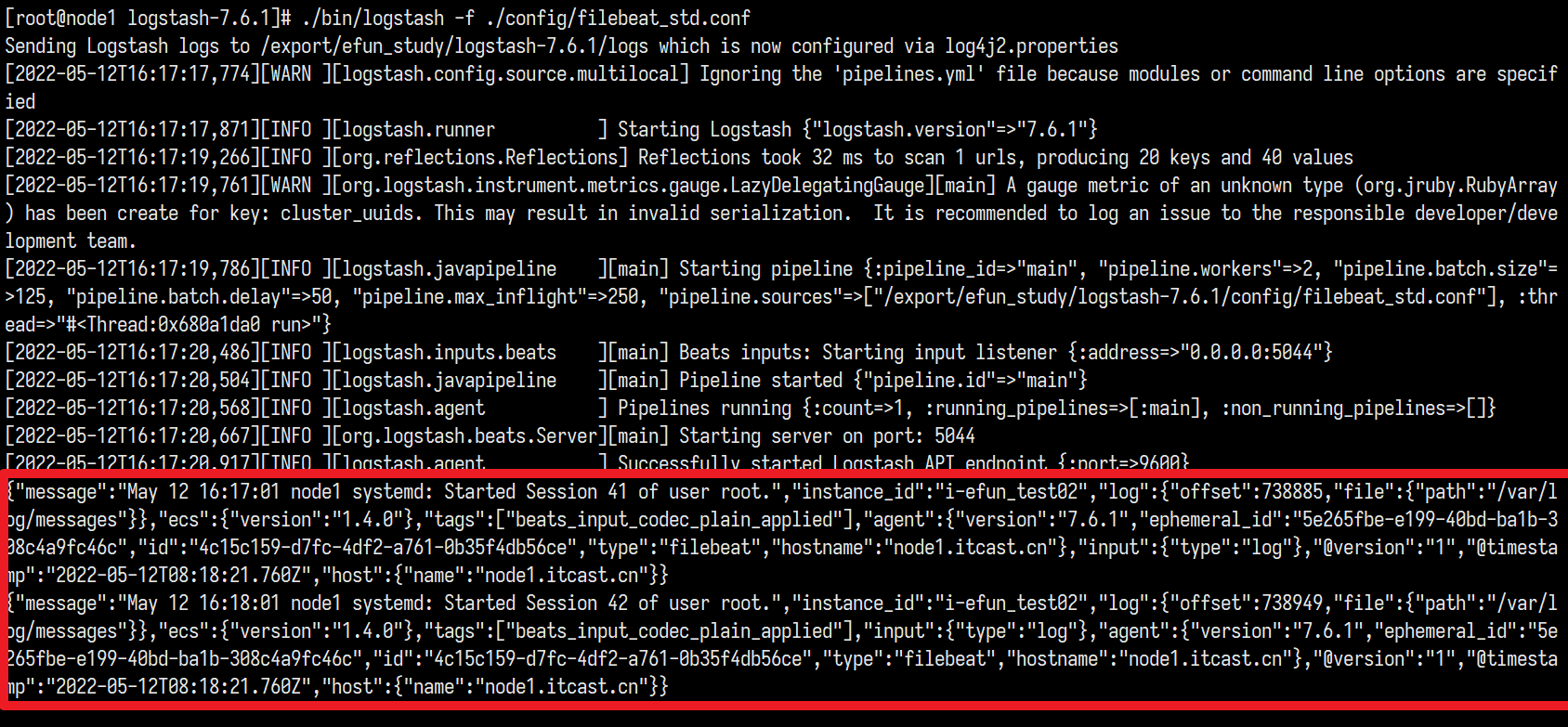
这时候logstash里面已经出现数据, 就证明成功了
插件简单使用
mutate插件
在/config新建一个std_std.conf
1 | input { |
第一次跑起来
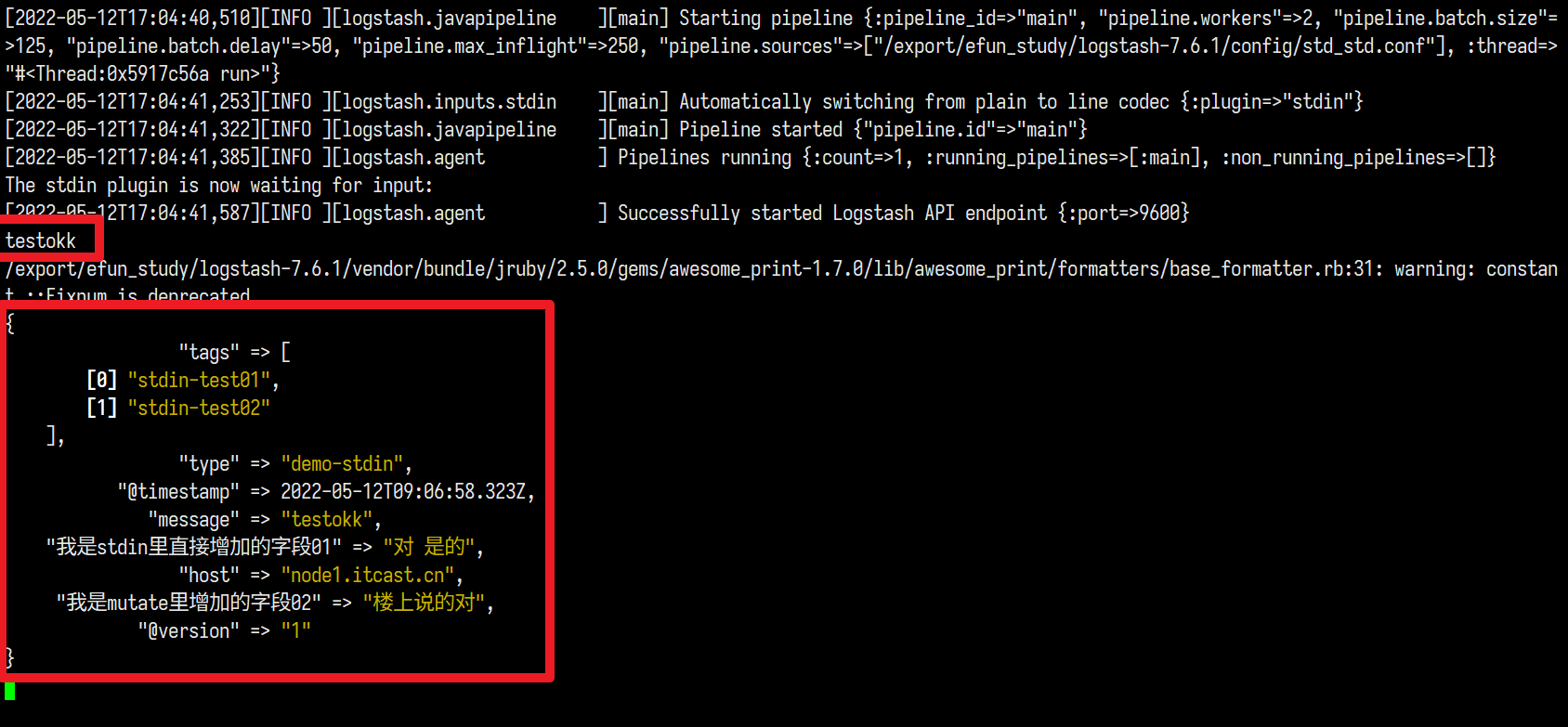
我们加一个 remove_field => [ "type" ]之后再跑一次
1 | input { |
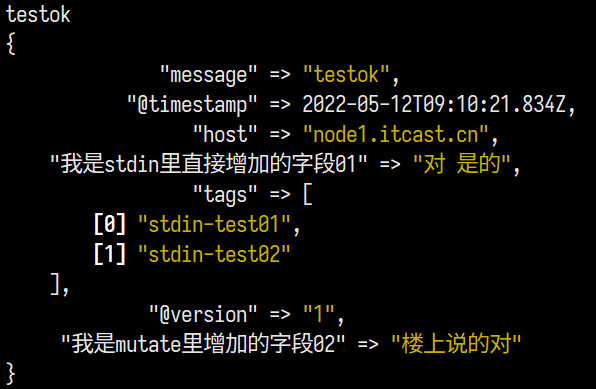
如预期, type字段已经被删除掉了
date插件
建 std_std_date.conf后再跑
1 | input { |
跑
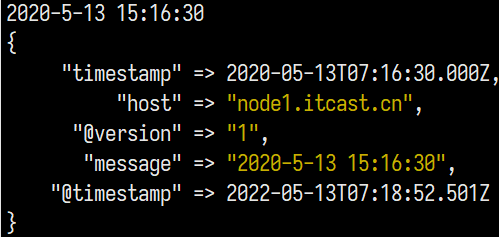
这里由于我本人理解不到位, 刚开始把
target => "timestamp"漏掉了, 导致未能成功跑出结果
drop插件
去公司了和何老师好好交流一下再补





